分布式系统一致性的发展历史 (四)
Eventual Consistency
Eventual Consistency这个一致性级别是Amazon的CTO Werner Vogels在2009发表的一篇论文里提出的[1],他是Amazon基于Dynamo等系统的实战经验总结的一种很务实的实现。因为不是学校里计算机科学的教授提出的, 所以它并不像前面介绍的各种一致性模型一样特别学院化,这个一致性模型没有非常清晰的符号化的模型。不过没关系,因为它简单所以即便没有符号化定义,他也非常容易理解。
在原文中,Werner Vogels的解释如下:
Eventual consistency. This is a specific form of weak consistency; the storage system guarantees that if no new updates are made to the object, eventually all accesses will return the last updated value. If no failures occur, the maximum size of the inconsistency window can be determined based on factors such as communication delays, the load on the system, and the number of replicas involved in the replication scheme. The most popular system that implements eventual consistency is the domain name system (DNS). Updates to a name are distributed according to a configured pattern and in combination with time-controlled caches; eventually, all clients will see the update.
这里所讲的Weak Consistency不是我们之前1986年Dubois, Scheurich和Briggs的论文里提到的Weak Consistency[2],这里是比较通俗意义的比较弱的一致性。Werner Vogels意思是最终所有进程都会看到last updated value。这个last updated value说明对于非并发的写入是遵循last write win的逻辑,对于并发写入我们没有规定顺序,比如下图中,左边P1和P2的两次写入分别写入1和2,因为两个写入操作有先后无重叠,所以last updated value一定是2。对于下图右边两个写入是有重叠并发的,这时候last updated value可以是1或者2任何一个。
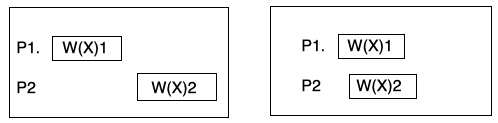
Eventual Consistency不要求其他进程看到一样的历史,因此对于上图左边的情况,P3可以看到X的历史是 1-2, P4可以看到2-1-2, P5甚至可以看到1-2-1-2-1-2,而这些都是符合Eventual Consistency的。对于右图的情况,所有进程无论中间看到什么,最终所有进程必须最后看到结果是1,或者最终全都看到2。
大家可以看得出来,“最终”是一个模糊的,有不确定的耗时的概念,他是没有明确上限的。Vogels提出这个不一致的时间窗口可能是由通信延迟,负载和复制次数造成的。但是最终早晚所有进程的观点都一致,这个不一致的时间窗口可能是几秒也可能是几天,比如一次写入在多个节点上不一致,可能几秒钟之后复制到了其他节点,也可能几天后的另外一次读才触发了一次anti-entropy的修复。
我稍微总结了一下,对Eventual Consistency给出一个严格定义
- 对于一个进程P1,他自己的读写遵循program order。
- 如果P1 W(x), 然后P2 W(x),其它进程允许看到随意顺序,但是最终都会看到P2 W(x)的值。
作者还提及到Eventual Consistency有一些变体,我觉得有两个变体很值得给大家分享一下。
Causal Order变体
第一个变体是部分实现Causal Order的变体。
比如P1 W(x)之后,如果发了消息给P2通知了这次写(P1的写和P2的读有causal关系),P2的对x的写一定要覆盖P1的写(某些操作存在causal偏序关系)。而对于其他进程P3,如果P1和P3没有casual关系,则P3可以看到任意的写入顺序,P3自己的写入即便是在P1之后,也可能被P1所覆盖。也就是说,在工程实现中Eventual Consistency之后,适当对部分操作增加约束可以达到部分操作具备Causal Order。这里说的是部分操作,不是全部操作,通常我们可以对一些关键的有因果关系的操作或者某些关键进程加上Causal Order的约束,如果全部操作都实现,那就不是Eventual Consistency了,彻底升级变成Causal Consistency了,我们也得不到Eventual Consistency带来的性能优势了。
Session Consistency变体
第二个变体是Session Consistency。对于某些应用会有session的概念,比如某个客户端建立的数据库连接就是一个session。这是一个客户端视角的变体,假设客户端是P1,数据库是P2和P3两个节点,x初始值为1,那么P1的W(x) 2会发给P2和P3,不管P2和P3之间如何复制同步x,P1下次对x的读取应该会得到2.
Dynamo和Cassandra
作者最后在论文中拿Dynamo举了个例子,其实Cassandra也是一样的模型。我们引入三个变量
- N 一个数据要复制多少份
- W 完成写入多少个副本才算写入成功
- R 读取多少个副本并且数据一致才算读取成功
对于一次写入,W超过N的一半的时候,一次写入能确保至少过半的节点已经持久化了这次写入。然后对于一次读取,如果R要求也超过N的一半,那么这次读取必然可以和上次W的节点存在交集。只要存在交集,无论是通过版本号,时间戳,或者多读若干个节点(N > R的时候),集群总是有办法能够返回上次最新的写入。对N过半的读写称之为Quorum。
实际工程中有很多的优化,比如Cassandra从多个节点上并不是直接读取数据,是读取数据的digest,这样可以减少传输量,只有当digest不一致的时候,才去读取完整数据进行时间戳对比来完成read repair。
总结 Consistency Models
至此,本文系列讲述了以下几种经典一致性模型
Linearizability: 所有进程看到的事件历史一致有序并符合时间先后顺序, 单个进程遵守program order。有total order。工程实现通常是硬件或基础设施自动同步。
Sequential: 所有进程看到的事件历史一致有序但不需要符合时间先后顺序, 单个进程遵守program order。有total order。工程实现通常是硬件或基础设施自动同步。
Causal: 所有进程看到的causally related事件历史一致有序, 单个进程遵守program order。不对没有causal关系的并发排序。工程实现通常是硬件或基础设施自动同步。
PRAM: 所有进程互相看到的写无序, 除非两个写来自一个进程 (所以叫pipeline)。不对跨进程的消息排序。工程实现通常是硬件或基础设施自动同步。
Weak: 所有进程互相看到的写无序, 除非两个写来自一个进程 (所以叫pipeline)。不对跨进程的消息排序。工程实现通常是软件命令硬件同步,或者调用方指令基础设施同步。
Eventual: 所有进程互相看到的写无序, 但最终一致。不对跨进程的消息排序。工程实现通常使用N/R/W三个参数控制一致性。
其他还有一些在分布式系统中不太常用的一致性模型在此就不做介绍了。 至此我们讲的这些一致性模型都是基于单个值的读写模型,接下来我们会讲另外一类一致性模型,是基于多个操作的具有隔离性的事务的一致性模型。
参考
- Werner Vogels “Eventual Consistency” Communications of the ACM, January 2009, Vol. 52 No. 1, Pages 40-44 10.1145/1435417.1435432
- Michel Dubois, Christoph Ernst Scheurich, Fayé Alaye Briggs. “Memory access buffering in multiprocessors” 0884-7495/86/0000/0434S01.00 © 1986 IEEE