分布式系统一致性的 program order
Overview
在很多关于分布式系统的论文中我们都会涉及一个program order的概念。在我的分布式系统一致性的发展历史系列中的第一篇里对这个问题作了一些解释。但是后来我发现几乎每篇文章中都会出现这个概念,为了读者方便,我觉得有必要单独写一个短文章来描述这个概念,并在这些文章中加入链接到这篇文章。
History
开始之前,首先解释一下event,history和schedule。我们程序指定的操作顺序,在运行期被调度和执行的时候可能会改变操作的顺序。每个操作执行的结果就是event。把所有的e排序得到的一个顺序叫做history,也有一些论文称之为schedule,其实都一个意思。
Leslie Lamport在1979年的论文 “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Program”[1], 提出了Sequential Consistency的概念, 其中用了program order的概念
A multiprocessor is said to be sequentially consistent if the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.[How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs by Leslie Lamport ,1979]
sequential order是指被系统interleave和re-order之后的执行顺序,the order specified by its program是指符合逻辑期望的顺序。
我们来举个例子,比如两个进程P1, P2上发生的事件分别是1, 2, 3, 4和5, 6, 7, 8, 并且我们做两个假设:
-
假设1: 1-2-3-4这个四个事件是有因果关系的,5-6-7-8也是。比如,在单个进程上事件1代表写X为1,事件2代表对X++,那么二者存在因果关系。
-
假设2: 1-2-3-4所操作的变量和5-6-7-8所操作的变量没有交集。比如P1只操作a和b两个变量,P2只操作c和d。
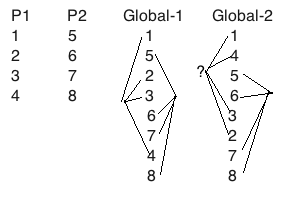
如上图所示左边两列是P1和P2的局部的program order,右边global-1和global-2两列是两种从全局让事件交错排序出来有序的集合, 这个过程叫做arbitrary interleaving。global-1这一列表示这样的交错是符合Sequential Consistency的, 因为P1和P2的原始顺序在交错中仍然得到了保留,这个过程叫做arbitrary order-preserving interleaving。但是global-2就不一定符合Sequential Consistency, 其中1,4,3,2的顺序在单个进程P1上已经不符合”program order”。
但是如果我们改变第一个假设,我们假设1-2-3-4之间没有因果关系,比如这四个事件分别是对四个不同的变量写入一个值,那么我按照1-4-3-2去执行也没有影响到最终结果,那么global-2也是符合program order的。
如果我们改变第二个假设,我们假设P1(1-2-3-4)和P2(5-6-7-8)同时操作了一个变量X,有可能P1的事件2对X写入0,P2的事件6对X++。也就是说,2和6两个事件存在因果关系,事件2发生在事件6之前或者之后,会影响X的结果。更具体一点,比如P1需要对某个用户银行开户,初始化余额为0,P2要对他这个新开账户存入1美元。那么这两个操作必须在全局上有特定的顺序,否则就会产生逻辑错误。
这两个假设其实就是program order的两个方面,第一点,系统对单个进程上的操作进行重排序(re-order)产生的事件历史,不应该影响单个进程上的程序逻辑正确性。第二点,系统对多个进程上的操作进行交错排序(artitary order-preserving interleaving)产生的历史事件,不应该影响进程之间的程序逻辑正确性。第一点比较容易定义,第二点其实挺难给出精确的数学定义的,我们通常会使用potential casual的关系来定义,但是实际上经常会过度,potential causal不代表一定会causal。我这里也就不展开也不尝试给定义了,大家理解即可。
为什么?
看到这里,不熟悉多线程编程的工程师可能会问, 为什么P1和global-2中对于3和2的顺序有不同的观点? 为什么program order还会变? 我这里稍微解释一下CPU读写内存的工作原理, 熟悉C++/Java内存模型的程序员可以跳过这部分.
下面是典型的Xeon两路处理器的样子. 每个处理器的每个core有自己的L1/L2 cache, 所有的core共享L3 cache, 然后两颗处理器之间通过环形QPI通道实现cache coherence. 这样, 整个cache系统就成为了所有处理器核心看内存的窗口, 或者说是唯一事实.
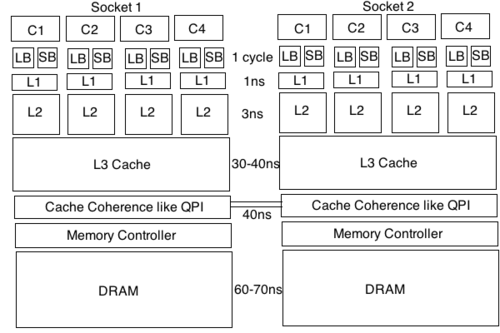
处理器的一个cycle很快, 1ns都不到, 而内存访问很慢, 需要几百个cycle了, 就算是最快的L1的访问也需要三个cycle, 只有寄存器能跟得上CPU cycle, 所以为了充分利用处理器, 在core和L1之间插入了接近寄存器速度的MOB(Memory Ordering Buffers). 上图因为空间有限只画了Load Buffer和Store Buffer, 其实还有其他类型的buffer比如WCB(Write Combine Buffer).
Load Buffer, Store Buffer和WCB可以提高处理器整体性能. 比如你对一个线程间的共享变量做密集的循环, 这个变量的i++可能是发生在寄存器内或者Store Buffer内, 当循环结束的时候才写入L1/L2 cache, 然后通过QPI让另外的处理器看到变化, 在这个密集循环过程中另外一个处理是看不到这个变量的变化历史的. 还有就是如果你对三个变量写入, 那么三次内存访问需要大概900个cycle, 如果这三个变量地址连续, 那么很有可能他们碰巧在同一个64字节的cache line里, 那么处理器可能会把三个变量先写入Write Combine Buffer, 稍后合并成一次写操作回到cache和内存, 这就只需要300个cycle, 这种优化叫做Write Combine. Store Buffer和Write Combine Buffer提升了处理器利用率减少了写等待, 但是会导致一个CPU的内存写入对另外一个CPU的读取显现出延迟或者不可见. 这时候需要一个fence禁止reorder并等待flush结束. (Java里面volatile读写会放一个fence, 很多Java程序员认为volatile是让CPU直接访问主存不经过cache, 这是错误的观点).
从另外一个角度看, 因为解析地址和读取内存也是非常慢, 总共要几百个cycle, 有时候处理器在不破坏局部指令依赖关系的前提下可以直接更改执行顺序. 这种情况下处理器的乱序减少了等待时间, 提高了效率, 但是因为乱序会导致你会读到过期的数据. 就算是别的处理器已经flush了Store Buffer, 你也读不到最新的状态. 要读到最新的数据, 也需要一个memory fence禁止reordering并等待Load Buffer内的数据被清除. 大多数MESI协议的变体都会有一个invalidate queue, 其他处理器对cache line做的改动的都会作为消息(Invalidate消息)传递给这个处理器, 一个read fence可以把invalidate queue里之前所有的消息取出来去把load store和寄存器中的cache line清除掉, 来保证当前处理器可以读取到最新的数据.
所以, 处理器之间的可见性问题和乱序问题, 会让每个处理器对历史事件产生不同的观点. Memory fence虽然可以解决这个问题但是它会打破处理器的pipeline产生stall, 目前的主流服务器处理器有48个pipeline stages, 产生一次stall的代价非常高. 这就是为什么我们需要共享控制变量或者变量之间存在因果关系的时候我们才需要memory fence, 这也是为什么会有Causal Consistency和Weak Consistency模型, 我们将来会介绍.
参考
- Leslie Lamport. “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Program”. IEEE Trans. Comput. 28 (9): 690–691.