分布式系统一致性的发展历史 (三)
其实这篇文章4年前就写好了,但是一直没空去review它。最近正好不太忙,抽空就把它审了一遍发出来了。之前的文章篇幅比较长,以后我会写的短一些。
至此我们已经介绍过Sequential Consistency, Linearizability和他们的应用, 拜占庭将军问题和FLP理论. 这些模型相对而言比较严格, 导致在实现的时候遇到了很多性能问题, 实际在应用中, 除了一些关键事件需要Sequential Consistency或者Linearizability之外, 大多数情况下我们是不需要这么严格的一致性的, 因为全局的偏序关系会很大程度的影响并发. 而我们工程中有很多场景下对于一致性要求没有这么高, 所以九十年代前后又出现了一些新的不太严格的一致性模型.
本篇文章里我会介绍三个一致性模型: PRAM Consistency, Causal Consistency和Weak Consistency.
Causal Consistency 1991
PRAM的模型只能用于一致性要求比较弱, 没有进程间因果关系的场景中. 工程实现中很多时候P之间还是需要有因果关系的。举个例子,facebook上两个朋友可以并发的发出没有任何关联和依赖的两个独立的post, 其他用户的feed里看到这两个人的post谁先谁后并不重要, 我不需要建立post之间他们的全序关系. 但是有两个情况我们需要关心他们的顺序。第一个情况,如果一个人连续发了两个post,那么任何人的feed里都应该看到p1早于p2,这两个事件之间存在causal关系。第二个情况,如果A发了一个post, 然后B 对这个post发了一个reply, 这两个事件也有causal关系, 其他人接受到的这两个事件一定是有顺序的,一定是先看到post再看到reply. 我们称这样的因果关系叫做”causally related”, 与之对应的一致性模型叫做”Causal Consistency”, 这个模型是1991年由乔治亚理工学院的一批科学家提出的[2], 但是它的核心思想已经在更早的Leslie Lamport的那篇著名论文”Time, clocks, and the ordering of events in a distributed system”中已经描述过了, 只是Lamport Clock只告诉了我们potentially causally related事件如何按照一个全局的Logical Clock得到偏序集, 并没有提出一个一致性模型,并且Lamport Clock也无法直接找到具有causal related的关系。比如Lamport Clock里两个事件的timestamp分别是10和11,我们是不能说10对应的事件和11对应的事件是有causal关系的。
下面简单介绍一下Causal Consistency的模型, 在这篇论文中[2]作者回顾了Sequential Consistency和PRAM Consistency然后提出了介于二者之间的一个Causal Consistency模型,定义如下:
- 基本模型类似于Herlichy & Wing 在定义Linearizability中用到的FIFO模型 [3]
- Li: 某个进程Pi的本地执行历史
- o1 > o2: 在某个Pi上操作o1在program order上早于o2
- H: {L1, L2 …. }的集合。
那么对于Linearizability Consistency和Sequential Consistency来说,所有的Pi都应该可以看到一个一样的序列化S, 是H中所有操作的total order,并且满足所有的Li中的program order。
而对于前面介绍的PRAM来讲,每个Pi都会有自己的Si, 并不会有一个全局的唯一的S, 并且所有的Si中的写操作之间也不是全序关系,只是在“同一个进程Pi中的写”这个子集内之间有total ordering的关系.
对于Causal Consistency来说, 每个Pi都有自己的Si, 但是所有的causally related的写操作作为一个子集,是有全序关系的, 并且这些操作在所有进程上观察到的顺序都一样. 这就是Causal Consistency和PRAM的区别.
注意一点, Causal Consistency的模型中的causally related是指潜在的, 实际业务中是否真的是causally related是要看具体情况的. 因为Causal Consistency和这个系列文章中目前所出现的所有模型一样都是自动化的模型,不需要开发人员介入,所以模型看到P1 W(x)1, P2 R(x)1, P2 W(x)2, 模型只能假设他们之间是causally related, 而实际上P2的写入尽管按照program order发生在读取之后, 但是这个写入是否是基于前一步读取的结果, 这个取决于业务, 只有开发人员和程序知道是否二者有依赖或者因果关系, 系统只能把这种potentially causally related当做causally realted才能自动满足Causal Consistency. 如果要更加精细控制, 就要引入开发人员自己在程序中手动控制了, 后面的Weak Consistency就是一个需要手动控制的模型.
通俗一点讲, 在一个分布式系统中, Causal Consistency就是”reads respect the order of causally related writes”. 这个定义的关键在于什么是causally related, 两个读写操作之间怎样才算是有潜在的因果关系. Leslie Lamport的Lamport Clock是最早引入Causal Consistency的思想, 后来出现的Vector Clock是应用最为广泛的一个识别Causal Consistency事件的算法.
Vector Clock的出现要追溯到80年代末两篇论文[4][5](早于1991年Causal Consistency模型的出现). Vector Clock可以很好地找出消息之间是否有潜在的因果关系, 如今在各种分布式系统中应用非常广泛. 假设有n个进程, 每个进程的Vector Time就是一个模长为n的向量, 元素初始全部为0, 记做VT(Pi),向量内第i个元素记做VT(Pi)[i]. 每当Pi发送一个消息的时候, VT(Pi)[i]就增加1并把这个向量连同m一起广播出去, 记做VT(m), 关键的是下一步, 如果Pj接收到这个消息, Pj需要合并VT(m)和VT(Pj)两个向量:
对于任何k ∈ 1 … n : VT(Pj)[k] = max ( VT(Pj)[k], VT(m)[k] )
因此, Vector Time总是在各个元素上单调递增, 表达了每个进程发送了多少个消息, 然后我们就可以用VT来找出潜在的先后关系了. 规则如下:
- VT1 <= VT2, iff 任何i都有VT1[i] <= VT2[i]
- VT1 < VT2, if VT1 <= VT2 and 存在i使VT1[i] < VT2[i]
如果两个消息之间存在潜在的因果关系, 比如m1早于m2, 那么一定会满足VT(m1) < VT(m2). Vector Clock可以精确地表达潜在的causally related关系.
举个例子, 一个系统中有三个进程, 其中P1, P2同时分别发出一个消息m1和m2. 那么VT(m1) = (1, 0, 0), VT(m2) = (0, 1, 0). 如果P3收到了这两个消息m1, m2, 那么P3会得到VT(P3) = (1, 1, 0), 而且P3认为m1和m2不是causally related, m1和m2是两个并发写, 顺序无关.
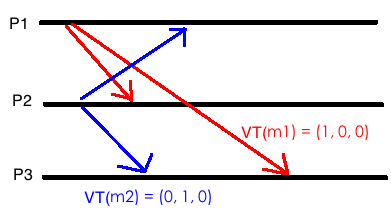
如果P3收到了m1和m2, 那么不管m1/m2谁先到达都无所谓. Causal consistency不要求全局历史, 不关心并发写的顺序, 所以性能会比Linearizabiltiy好很多. 而且顺序也不需要全局一致, 比如上main这种情况下, P3如果读操作读到m1然后再m2, , 如果还有一个P4读到了m2再读到m1, 那么P4的读和P2的写也是符合causal consistency的. 对于无causal关系的写事件,P3和P4允许有不同的观点。
如果像下面这样P1发了消息m1, 然后P2收到m1之后P2再发出m2, 那么m1和m2就是潜在的causally related messages.

Vector Clock就应该能检测到这种情况. 以下是过程: P2收到m1的VT(m1) = (1, 0, 0), 此时VT(P2) = (0, 0, 0), 然后合并结果为 VT(P2) = (1, 0, 0), 这时候如果P2再发出m2, 那么VT(m2) = (1, 1, 0). P3如果收到了m1和m2, P3就可以发现VT(m1) < VT(m2), 因为(1, 0, 0) < (1, 1, 0),并推测m1和m2存在causal关系,P3一定要先处理m1再处理m2. 如果P3先收到并处理了m2,再收到m1的话可能要特殊处理m1,比如丢弃m1.
P3接收到m1/m2相当于两次读操作, 在第一个例子中, 两个读是基于无因果关系的两个写操作, 所以没有write orders可以让read来respect, 但是第二个例子中, 两个读是基于因果有序的两个写操作, 所以要回到最初这句话: “reads respect the order of causally related writes”. 现在我们给出对Causal Consistency的严格的数学定义你会更容易理解了:
A causality order o1 ⤳ o2 if and only if one of the following cases holds:
- o1 precedes o2 for some process Pi
- o2 reads the value written by o1
- there are some operations o’ such that o1 ⤳ o’ ⤳ o2
Vector Clock有很多变体, 比如有些会在接收到消息的时候也自增, 但是本质上都是通过一个Vector监测到消息被谁更改了多少次. 我们来看一个实际应用: Riak.
Riak中保证Causal Consistency其实就是Conflict Resolution. 如果客户端发现三个节点返回的一个数据的Vector Clock vt1 vt2 和 vt3 如果是causally related的, 那么Vector Clock可以找到这三个不同的值谁是因谁是果, 然后自动修复(read repair with active anti-entropy), 最终客户端就可以得到正确的结果, 如果不是, 那么说明这三个节点收到了并发无因果关系的写, 那么相当于这个数据有了siblings, 那么实际上客户端可以挑一个节点的值作为正确结果. (disclaimer: 这并不是Riak唯一的Conflict Resolution方法, Riak也支持timestamp和dotted version vectors, 还可以禁止siblings)
Causal Consistency因为只约束有因果关系的写和读, 对于不是causally related writes是不关心顺序的, 比如Vector Clock中没有任何操作是悲观阻塞的, 也不像Paxos那样要多个回合, 所以Causal Consistency的实现通常性能比较好. 但是Vector Clock如果在进程数量特别多的时候会有膨胀效应, 尽管有一些对Vector Clock压缩的算法, 但是Vector Clock仍然不是非常适合大量进程的情况. 接下来我们介绍一个更弱更简单, 但是没有这个问题的一致性模型PRAM.
PRAM, 1988
PRAM是Pipelined RAM的缩写. Princeton大学的Richard Lipton和Jonathan Sandberg在1988年的一篇论文中第一次定义了PRAM 的一致性模型[1].
当时的计算机一般是CRAM模式(Coherent Memory System), 这样的系统对于程序员来讲非常友好, 但是由于操作在总线上会阻塞所以性能很差, 任何优化都会导致硬件设计很复杂, 使硬件成本居高不下. 而PRAM非常简单, 他的核心思想是通过隔离减少进程间交互来提升性能。PRAM模型下进程不再关心写和后继的读操作的因果关系, 所有的写操作都在彼此独立的pipeline里, 因此任何一个进程观察到的某个进程上的写是局部一致有序的. 但是这不意味着所有进程的写都有一个全局顺序. 举个例子

这个例子中P3 P4 P5看到的P1和P2上的对同一个变量x的写入顺序是不同的,但是如果只看P1对x对写入顺序,大家观点都是一样的,都是先W(x)1然后W(x)2,如果只看P2对x对写入也都是一样正确的,都是W(x)3 然后W(x)4,所以这是符合PRAM一致性的。但是对于P6,他对P1对x对写入顺序观点是违反了P1的program order的,所以P6的存在是不满足PRAM的。
再举一个例子来说明PRAM比Sequential Consistency要求弱化在哪里。

这个例子中假设P2读取x之后通过一些计算再写入x。这个例子不满足Linearizability因为W(x)1和W(x)2在P4上顺序不对. 然后也不是Sequential Consistency因为P3和P4对x的写入观点不一致, 然后也不是Causal Consistency因为W(x)1和W(x)2是有causal relation, 必须先W(x)1然后再W(x)2, 但是P4两次读取X的结果不遵循这个顺序. 然而, P4是符合PRAM的, 因为W(x)1和W(x)2在两个不同进程上, 所以不需要有全局先后顺序. 简单讲, PRAM模型下每个节点的处理是在其他节点看来一致的, 但不考虑节点之间的处理依赖. 这是一个非常简单的模型, 但是适用场景比较有限,它假设P之间不存在处理的依赖关系。比如Kafka在每个partition上消息有序,但是在整个topic上是无序的.
Weak Consistency, 1986 – 1989
目前包括PRAM在内我们所有介绍过的一致性模型都是系统自动同步的, 这意味着硬件实现上要有很多复杂的设计,而效率一定会收到影响。还记得我们之前介绍Sequential Consistency的时候提到的reordering和memory fence的介绍么? 在Sequential Consistency被定义的时候, 科学家们设计的模型是每个指令都要由硬件去保证顺序和同步, 但是性能会很糟糕, 所以我们今天几乎没有任何一款处理器会在硬件自动提供这样的一致性. Weak Consistency说白了就是硬件提供Memory Fence这样的指令, 让开发人员自己在软件中去发送指令, 然后硬件可以理解这样的指令并同步内存.
1986年Dubois, Scheurich和Briggs发表了论文Memory Access Buffering in Multi-processors提及到了在多路处理器中weak ordering的概念. 1989年Adve和Hill的论文 Weak Ordering – A New Definition中再次定义了Weak Consistency.
1986年的论文中的定义为:
- accesses to global synchronizing variables are strongly ordered
- no access to a synchronizing variable is issued by a processor before all previous global data accesses have been globally performed
- no access to global data is issued by a processor before a previous access to a synchronizing variable has been globally performed.
其实说的就是个fence。后来1989年的论文中,给出的新定义更加简洁:
Let a synchronization model be a set of constraints on memory accesses that specify how and when synchronization needs to be done. Hardware is weakly ordered with respect to a synchronization model if and only if it appears sequentially consistent to all software that obey the synchronization model.
换句话说,Weak Consistency应该是软件和硬件的一个契约, 硬件本身不支持Sequential Consistency但是开发人员的软件可以利用硬件的能力, 通过软件的同步指令实现Sequential Consistency, 这点不用于之前介绍过的硬件自动实现的一致性模型. Weak Consistency的工程实现在围观多路处理器中就是fence,硬件约定CPU reordering不能跨越fence,而软件负责插入fence。在宏观分布式系统中, 这相当于一个flush/drain的概念, 目的就是应用自己决定什么时候(synchronization model)来执行flush/drain,写数据的进程要把write buffer内的内容批量flush出去,读数据的进程把cache都drain.
尽管论文里也是把Weak Ordering作为一种consistency model来讲的,但是我觉得他其实算不上,他只能算是一个工程实现的模式。其实你的synchronization model如果要求任何操作都要按照实际发生顺序排序,那么相当于你任何操作都要flush/drain,这就变成Linearizability了。根据你的synchronization model不同,weak ordering可以实现不同级别的一致性。
参考
- Richard J Lipton and Jonathan S Sandberg. “PRAM: A scalable shared memory” Princeton University, Department of Computer Science, 1988.
- Mustaque Ahamad, Gil Neiger, James E. Burns, Prince Kohli, Phillip W. Hutto. “Causal memory: definitions, implementation, and programming” Distributed Computing, 9(1):37–49, 1995
- Herlihy, Maurice P.; Wing, Jeannette M. (1987). “Axioms for Concurrent Objects”. Proceedings of the 14th ACM SIGACT-SIGPLAN Symposium on Principles of Programming Languages, POPL ‘87. p. 13
- Kenneth Birman, Andre Schiper, Pat Stephenson. “Lightweight Causal and Atomic Group Multicast” ACM Transactions on Computer Systems, Vol. 9, No. 3, August 1991
- Colin J. Fidge. “Timestamps in Message-Passing Systems That Preserve the Partial Ordering” In K. Raymond (ed.). Proc. of the 11th Australian Computer Science Conference (ACSC’88). pp. 56–66.
- Michel Dubois, Christoph Ernst Scheurich, Fayé Alaye Briggs. “Memory access buffering in multiprocessors” 0884-7495/86/0000/0434S01.00 © 1986 IEEE
- S. V. Adve and M. D. Hill, “Weak ordering-a new definition,” [1990] Proceedings. The 17th Annual International Symposium on Computer Architecture, Seattle, WA, USA, 1990, pp. 2-14, doi: 10.1109/ISCA.1990.134502.