分布式系统一致性的发展历史 (二)
- Consensus问题
- 两阶段提交和三阶段提交, Two Generals Paradox, 1975 - 1981
- Byzantine Generals Problem
- FLP Impossibility, 1985
- 大名鼎鼎的Paxos算法 1990 – 2001
- Uniform Consensus
- 小结
- 参考
- 系列文章目录
在本系列第一篇文章中我们提到了Lamport Clock如何启发人们在分布式系统中开始使用新的的思维方式, 并介绍了Sequential Consistency和Linearizability. 本篇文章会稍微停留一下, 我们会介绍他们所延展出来的一些应用问题来让大家更好的理解这两种一致性模型, 然后再下一篇里再继续介绍其他一致性模型. 本篇内容可能稍微超过了一致性问题的范畴, 但是本系列后面介绍的一致性模型的应用都没有这么丰富, 所以本篇可能是本系列中最接近实际应用的一篇, 也是最长的一篇, 很难一次看完, 你可以收藏后慢慢看.
在本篇正式开始之前, 我们先定义一下分布式系统中的网络和故障的模型, 这部分稍微有点枯燥, 但是很重要, 了解他们才能继续阅读本文. 为了缩短篇幅,我把这部分内容摘到一篇独立短文,请先阅读分布式系统中的网络模型和故障模型.
Consensus问题
之所以要介绍Consensus问题是因为Consensus问题是分布式系统中最基础最重要的问题之一, 也是应用最为广泛的问题, 他比其他的分布式系统的经典问题比如self-stabilization的实际应用要多, 我们可以通过介绍Consensus问题来更加深入得介绍一下之前提到的Linearizability和Sequential Consistency.
Consensus所解决的最重要的典型应用是容错处理(fault tolerannce). 比如在原子广播(Atomic Broadcast)和状态机复制(State Machine Replication)的时候, 我们都要在某一个步骤中让一个系统中所有的节点对一个值达成一致, 这些都可以归纳为Consensus问题. 但是如果系统中存在故障, 我们要忽略掉这些故障节点的噪音让整个系统继续正确运行, 这就是fault tolerance. Consensus问题的难点就在于在异步网络中如何处理容错.
Consensus问题的定义包含了三个方面, 一般的Consensus问题定义为:
- termination: 所有进程最终会在有限步数中结束并选取一个值, 算法不会无尽执行下去.
- agreement: 所有非故障进程必须同意同一个值.
- validity: 最终达成一致的值必须是V1到Vn其中一个, 如果所有初始值都是vx, 那么最终结果也必须是vx.
Consensus要满足以下三个方面: termination, agreement 和 validity. 这三个要素定义了所有Consensus问题的本质. 其中termination是liveness的保证, agreement和validity是safety的保证, 分布式系统的算法中liveness和safety就像一对死对头, 关于liveness和safety的关系, 我们将会在本系列后面的文章中介绍. 所有需要满足这三要素的问题都可以看做是Consensus问题的变体.
在异步网络中, 如果是拜占庭式故障, Paxos和Raft是没有办法解决的, (直到Babara Liskov在2002年提出PBFT[1]我们才可以在放松liveness的情况下解决此类问题, 为此Barbara Liskov获得了图灵奖. 我可能会在将来的文章中介绍PBFT). 对于一般的应用来说拜占庭故障出现的概率太低而解决的成本实在是太高, 所以我们一般不考虑拜占庭式故障. 我们主要是关注crash-recovery failure的模型下的异步网络. 这种情况下根据FLP理论, 只要有一个故障节点, Paxos/Raft都是有可能进入无限循环而无法结束的, 但是实际上这个概率非常低, 如果放松liveness的要求, 我们认为这种情况下Paxos/Raft是可以解决的. 以下介绍Consensus问题的时候我们都不考虑拜占庭式故障, 我们的故障模型是crash-recovery failures, 网络模型是异步网络.
在同步网络中因为所有节点时间偏移有上限, 所有包的传输延迟也有上限, 节点会在一个round内完成计算并且传输完成, 所以一旦超过一定时间还没有收到返回的消息, 我们就可以确定要么网络中断要么节点已经crash. 但是我们现实当中都是异步网络, 传输延迟是没有固定上限的, 当很长时间一个节点都没有返回消息的时候, 我们不知道是这个节点计算速度太慢, 还是已经crash了. 如果是这个节点计算太慢, 超时之后, 过了一会这个节点又把结果再发回来了, 这就超出crash-stop故障模型的范围了, 这种情况需要用crash recovery的模型来解决. 在异步网络中无法区分crash和包延迟会导致consensus问题非常难解决.
两阶段提交和三阶段提交, Two Generals Paradox, 1975 - 1981
两阶段提交(two phase commit) 或者又简称为2PC是解决consensus问题的一个方法. 在Paxos算法出现之前, Jim Gary在在Leslie Lamport那篇开山之作的同年1978年提出了two phase commit的概念[2], 图灵奖获得者Jim Gary是分布式事务的专家, 他所设计的2PC的主要用途是实现分布式事务, 让两个数据库或者队列参与同一个分布式事务. 这个过程中有Coordinator负责协调各个资源参与者(cohort)去提交或者回滚自己的事务. 首先coordinator会通知所有cohort告诉他们要提交的内容, 如果cohort写入成功(这时还没有提交), 那么cohort返回同意的应答给coordinator. 然后coordinator收集到全部的应答之后如果有任何一个应答是拒绝的(某个cohort写入失败), 那么coordinator就通知所有cohort回滚, 否则通知所有cohort提交.
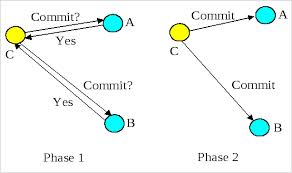
图片来源: Jboss
2PC最早的实际应用可能是八十年代的Tuxedo, 后来演化为XA/Open规范, 之后大多数商业数据库都开始支持XA/Open规范. 但是2PC的局限性很多人不太了解, 认为2PC是解决分布式事务的银弹. 其实2PC有一个很大的局限性: 2PC是一个阻塞协议. 假设coordinator给cohort A和B发出了事务内容, A和B都成功写入并返回同意的应答, 这时候coordinator和A都挂了, 然后B此时是无法得知现在事务已经被决定提交了还是要决定回滚了, B什么也不能干, 只能继续傻等, 直到coordinator恢复, 这时候就算重新启动一个新的coordinator也无法得知刚才的事务到底是什么状态了. 除非A也被恢复. 尽管事务阻塞了, 但是至此数据还是安全的, 只是事务在一个中间状态暂停了, B这个时候可以阻塞本地事务, 并锁住这条数据禁止访问.
尽管这样数据是安全的, 但是由于实际应用中事务阻塞是不可接受的, 如果cohort一直锁定着资源, 这样可能会导致整个系统不可用, 所以大多数实现都会超时回滚。但是这种情况下超时回滚这个事务就变成了heuristic transaction, 这时候A和B的数据就不一致了, 后面需要人工介入去改数据或者通过补偿去修复. 当你使用JTA的时候遇到个HeuristicMixedExceptionn, 那么很可能是这种情况发生了.
虽然2PC并不能像很多人想象的那样保证事务的一致性, 不考虑超时回滚的情况下它是安全的, 2PC可以保证safety但是不保证liveness. 为了解决这个阻塞问题, 后来又出现了3PC. 2PC的阻塞主要原因是当coordinator和cohorts同时crash的时候, 之前cohorts之间没有沟通过表决的结果, 他们只和coordinator表决过, 表决结果没有保留下来, 就算立即重新启动一个新的coordinator也无法判断刚才事务的状态, 所以他们会进入群龙无首, 进退两难的情况, 如果有一轮协商的过程, 那么即便coordinator挂了, 也可以再启动一个coordinator去询问cohorts上一轮协商的结果并把事务继续下去, 那就能解决阻塞问题了.
三年后出现的3PC[3]就是在2PC两个阶段之间插入一个阶段增加了一个相互协商的过程, 并引入了超时来防止阻塞. 这个中间阶段让coordinator发现全体写入资源并收到ACK之后, 先发一个prepare commit消息到全体cohorts, 当cohort全体都同意并返回ACK给coordinator之后, coordinator才发commit消息出去让cohorts提交.
如果prepare commit发出给A之后, coordinator和A都挂了, 如果立刻重新启动一个新的coordinator, 那么它发现B没有收到过prepare commit, 这个coordinator就可以发消息给所有cohorts去取消提交. B会回滚, 当A恢复回来之后可以去问coordinator或者任何一个cohort都会知道事务已经回滚. 这样整个事务就回滚了, 因为表决结果通过prepare commit消息可以保留在所有cohorts节点上, 这个情况是2PC无法解决的.
对于引入的中间阶段, 本身也是安全的. 比如A和B都写入资源之后, 如果coordinator没能发出prepare commit就挂了, 那么A/B会超时而回滚事务, 这是安全的. 如果coordinator 发出了prepare commit给A, 还没能给B发出, coordinator和A都挂了, 那么B也会超时回滚. 如果coordinator发出了prepare commit给A和B然后coordinator挂了, 这时候如果不启动任何coordinator那么A/B都会超时提交, 如果能再启动一个coordinator那么这个coordinator会发现所有节点都收到了prepare commit消息, 这个coordinator也会让所有节点提交.
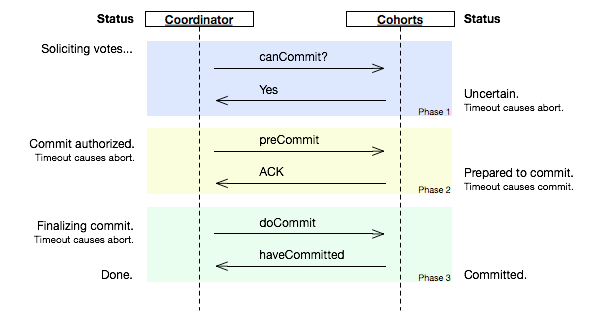
图片来源: wikipedia
实际上, 3PC没有什么实际应用, 高延迟是个很大的局限, 而且它还有一个更严重的问题, 那就是在网络分区的情况下也会出现事务不一致问题. 解释原因之前先介绍一下Two Generals Paradox问题.
Two Generals Paradox在1975年被提出[3], 但是广为人知还是靠分布式事务的专家Jim Gray在1978年的一篇文章”Notes on Database Operating Systems”[2]中再次提及这个问题(估计是因为Jim Gray名气太大), Two Generals Paradox这个名字也是Jim Gray起的. 问题描述的是有两个将军A和B分别处于敌军的东侧和西侧, 他们决定互相派信使, 好商量一个时间来同时发起攻击, 如果这个时间没有商量好, 一方先攻击了, 那么就会战败. 但是问题来了, 假设将军里没有叛徒(没有故障节点发出faulty message), 信使如果被中间的敌人抓住了, 会被直接被处死(会有丢包, 但是不会被篡改消息), 那么这两个将军能达成一致么? 好了, 看出来了吧, 这就是一个最简单的consensus问题. 这其实是一个弱化版本的拜占庭将军问题.
如果A送了一个信使m1去B商量一个进攻时间, B收到之后必须要这个信使回去告诉A自己收到消息了, 这是一个ACK应答消息, 没有ACK显然双方是无法达成确认一致的. 可是如果信使m1回去路上被抓住了, 被杀了. A这个时候等了半天没人回来, 他就会进入两难的境地, 到底是信使m1是去的路上被杀了, 还是回来的路上被杀了呢? 前者是B没有收到消息, A就不能在指定时间发起进攻, 后者是B已经收到了消息, A就必须要进攻. 实际上, 就算A收到了信使m1带回的B的ACK消息, 虽然A放心了, 但是B也不能放心. 因为B送走m1之后, B并不知道他的ACK有没有回到A那里, 如果回到A那里了, B认为自己可以发动攻击, 但是万一信使m1回去路上被杀了, A没有收到ACK, B岂不是会自己贸然发动进攻了? 怎么办?
有人说了, 让B交代信使m1, 你回去如果见到A了, 让他再送个信使m2过来告诉我一声, 我才放心. 信使m1回去了, 见到了A, A听了之后想了想, 说有道理, 然后又派了m2去B那里告诉B他收到B的ACK了, 读者看出来没, 这其实是第二个ACK, 这个ACK同样存在不确定因素, 和第一个m1附带的消息所面临的问题是一样的, 按照这个思路两个将军将会进入一个无限循环, 再去发ACK3, ACK4, 但是却无法解决问题. 根源就在于信使其实是一个异步网络, 而且会发生网络分区, 会有延迟和丢包.
这个问题告诉我们在一个异步不可靠的网络内想用简单的消息应答方式解决consensus问题是不可能的.
现在再回来解释3PC在网络分区下的不一致问题就容易了.假设coordinator第一轮发出了事务请求给所有cohorts, 结果所有cohort都锁定资源并写入成功, 而且都返回了同意应答. 第二轮的时候coordinator给所有cohorts都发出了prepare commit, 并收到了所有的ACK, 到了第三轮, 如果碰巧发生了网络分区, coordinator被隔离开, 无法和任何cohorts通讯, 超时之后, coordinator还没法把commit发出去, 它会认为cohort写入失败或者挂了, coordinator只能发出rollback请求给所有cohorts, 与此同时, 网络分区的另外一边cohorts那边发现coordinator联系不上了, 不给我们发commit了, 也超时了, 他们会选一个新的coordinator, 这个新的coordinator询问了所有节点发现都已经写入了并且表决同意过了, 那么这个新coordinator会发出commit.
碰巧这时候网络分区恢复了, 老的coordinator发出的rollback和新的coordinator发出的commit将会交错混杂在一起通过网络发给所有的cohorts. 结果将是一片混乱和不确定. 3PC虽然是非阻塞的, 但是他的超高延迟和缺乏网络分区的忍耐性让它的实际应用大打折扣.
2PC和3PC的主要缺点就在于他们的正确性都是假设了一个稳定的分布式系统模型. 1994年Sun的Peter Deutsch总结了7点分布式系统设计的常见错误假设, 后来James Gosling加了一条, 总结为8条:
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn’t change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
其中前两点就暗示了网络会有分区, 这时节点的故障判断非常困难. 2PC和3PC假设节点的故障判断非常容易, 就是超时, 并且假设节点故障之后不会自动恢复. 这种假设叫做crash-stop, 意思就是说我看不到你就认为你挂了, 有点像王阳明的”你未看此花时,此花与汝心同归于寂”, 在分布式系统中这种故障模型的假设是比较窄的. 你必须要假设你看不到他的时候, 他也可能活着, 说不定过了几秒钟他可能又给你发消息和你交互了. 在大多数情况下, 我们至少要把故障模型放大到crash-recovery.
Byzantine Generals Problem
前面提到的Two General Paradox实际上是一个弱化的Byzantine Generals Problem. 1982年, Leslie Lamport和另外两位科学家年发表了一篇论文阐述 “The Byzantine Generals Problem”[5]描述了更一般化的情况, 这种情况下不仅是网络会有故障, 节点本身也会有不按照逻辑执行的问题. 比如一个叛徒将军乱发消息或者不按照程序逻辑执行. 完整的拜占庭将军问题更加复杂, 必须加以特定场景的假设才能解决, 比如同步网络. 这个问题比较复杂, 本文只是简要介绍一下.
在同步网络中, 有3f+1个节点, 如果故障节点不超过f个, 那么这个问题是可以解决的. 我们这里不做严格证明, 但是可以简单解释一下原因.
我们考虑最基础的一种情况, 假设有三个将军, 只有一个叛徒. 如果A是叛徒, 那么A可能会给B发出进攻(1), 然后给C发出撤退(0)的命令. 当B和C互相同步信息的时候他们会发现两个不一致的信息. 但是B和C谁也无法判断谁是叛徒, 比如从B的角度来看, 他无法判断A是叛徒或者C是叛徒. 所以三个将军里有一个叛徒是无法解决的. 如果消息可以防止伪造, 那么在同步网络中叛徒达到1/3以上也是可以解决的. 下图右边从C的角度来看, 因为消息是真实无法伪造的, 那么很明显A是叛徒.
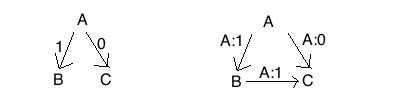
但是同步网络现实生活中太少, 如果要考虑在异步网络之中, 拜占庭将军问题是非常难解决的, 实际上根据FLP定理, 异步网络中是没有完全同时保证safety和liveness的一致性算法的. 但是在实际工程中我们如果放松liveness的要求, 是有实际可用的算法的, 这个算法进入无限循环的概率非常非常低. 1999年Miguel Castro和Barbara Liskov提出了PBFT算法(Practical Byzantine Fault Tolerance)[1], 这个算法可以在异步网络中不保证liveness的情况下解决拜占庭将军问题. 虽然不保证Liveness但是这个算法进入无限循环的概率非常低, 在工程中是完全可用的. 实际上他们实现了一个PBFT的分布式NFS文件服务器, 最坏的时候性能只下降了24%! 为此Barbara Liskov获得了2008年代图灵奖. 顺便提一句, 面向对象中的Liskov替换原则也是她提出的.

图片来源: 维基百科, Barbara Liskov 2010
FLP Impossibility, 1985
分布式事务作为Consensus类型问题, 在异步网络中非常难实现. 很多科学家们做了很多伟大的尝试, 包括2PC, 3PC, 等等, 但是1985年的时候, 一个重要的论文告诉了我们答案, 这就是著名的FLP Impossibility:[6]
No completely asynchronous consensus protocol can tolerate even a single unannounced process death.
在异步网络环境中只要有一个故障节点, 任何Consensus算法都无法保证正确结束. (这里unannounced process death是指一个进程停止工作了但是其它节点不知道, 其它节点认为是消息延迟或者这个进程特别慢. FLP假设没有拜占庭的故障节点, 那种情况过于困难, 故障在这里的定义是指进程停止尝试读取消息, 相当于crash-stop).
FLP中设计的模型是一个比现实情况要更可靠的模型, 当然了, 如果连更可靠的模型下一致性问题失效那么现实中更宽松的环境当然也是失效的. FLP还假设异步网络是可靠的, 尽管有延迟但是所有的消息都会投递一次且仅一次, 每个进程只会写入一次状态, 然后就进入了decision state, 这是一个很强的保证, 几乎没有任何网络能达到这样的可靠性. FLP并不要求所有非故障节点都达成一致, 只要有一个进程进入decision state就算达成一致了, 而且一致结果只能是属于{0, 1}, 这也是非常”容易”的agreement约束. 加上前面还提到最多只有一个进程发生故障, 相对于现实情况这已经是一个极端可靠的环境了, 但是在这样可靠的环境中仍然无法有一个一致性算法存在! 更不用说真实世界中的网络分区问题和拜占庭式问题了. FLP的证明告诉我们一致性算法的liveness是无法保证的, 如果你要safety那么就会可能进入无限循环, 每次状态变化都会可能保持当前的状态是可分支的(bivalent). FLP的严格证明很有趣, 但限于篇幅这里就不做介绍了. 有兴趣的同学可以去看原论文, 如果你觉得里面的数学语言比较晦涩, 可以看我写的一篇白话文的证明过程描述(https://danielw.cn/FLP-proof).

图片来源: MIT, Nancy Lynch, 两次Dijkstra奖获得者.
所有consensus问题最终在异步网络上只要有一个故障节点就都无法达成完全一致并结束. 这个理论的证明非常重要, 它终止了多年的争论, 现在你可以省省力气了, 不要再浪费精力去试图设计一个能在异步网络上能够容忍各种故障并保持一致的系统了. 比如分布式事务是永远无法实现单体应用级别的一致性的.
无论是Paxos还是Raft算法, 理论上都可能会进入无法表决通过的死循环(但是这个概率其实是非常非常低的), 但是他们都是满足safety的, 只是放松了liveness的要求, Barbara Liskov的PBFT也是这样. 在实际应用中, 上下游系统的一致性除了通过2PC或者Paxos Commit来实现, 我们也可以通过其他方式来实现最终的一致, 来避免2PC的缺点. 现实中你不得不接受短时间的不一致在分布式系统中是一种常态的事实. CAP理论的提出者Eric Brewer曾经这样说过:
So the general answer is you allow things to be inconsistent and then you find ways to compensate for mistakes, versus trying to prevent mistakes altogether. In fact, the financial system is actually not based on consistency, it’s based on auditing and compensation. They didn’t know anything about the CAP theorem, that was just the decision they made in figuring out what they wanted, and that’s actually, I think, the right decision.
举个例子, 实际上你从A银行往B银行转账实际上是没有两阶段提交或者分布式事务的, 金融行业是一个古老的行业, 在计算机出现之前银行就已经出现了, 金融行业有一点非常值得我们借鉴, 那就是WORM(write once read many). 金融行业把不一致当做常态而非异常. 举个例子, 会计记账的时候, 如果发现前面有一笔预付记录或者错误记录, 会计不会用橡皮抹掉那条记录再改成正确的, 会计只会在最后面加一笔记录来抵消前面的错误, 或者按照差额加一笔抵冲的记录. 任何记录只能写入一次, 然后再也不会改变. 我们假设没有人民银行作为中间节点, 把转账简化为A银行直接给B银行转账, 在转账过程中如果A已经扣款并通知了B, 但是B发现这个账号由于洗钱被锁定了, 不能入款, 那么B返回拒绝消息给A, 这时候A可以再追加一笔补偿交易, 把刚才扣掉的钱补偿回来. 整个过程可能是几秒钟, 也可能是几分钟, 也有可能是第二天(比如网络故障, 重试多次后放弃, 对账时发现). 在任何一个步骤发生故障, 用户都会经历一定时间的不一致, 从前面的讨论我们知道2PC如果允许超时回滚, 2PC也无法消除这个不一致的时间窗口, 但是只要有历史记录我们就可以通过自动补偿或者每日对账去补偿, 让数据重新一致. 这种事务可以很好地忍耐各种故障, 包括网络分区, 只要每个消息都有全局唯一的id或者消息是幂等的即可. 当网络恢复时任何一个节点都可以根据消息id轻松地去掉重复的消息, 当消息丢失时, 可以稍后重试或者每天对账.
如果事务包含特别复杂的计算, 或者涉及了线下的物流或者多方交易, 那么这样的事务可能需要几天才能完成, 这种长事务(Long Lived Transaction) 在2PC中更是无法处理, 我们总不能去锁定这些数据几天吧? 1987年普林斯顿大学的Garcia-Molina和Salem发表了一篇论文提出了saga的概念. 一个长事务T中的操作可以拆分为彼此独立的本地事务T1, T2, T3, 那么就可以称之为saga. 其中的每一个Ti都有一个相应的补偿事务Ci. 如果部分Ti失败了需要Ci来修复回原始状态, Ci不会直接把数据库改回原先的状态, Ci通常是像前面说的会计的做法追加修正内容去抹平Ti带来的变化. 下图中事务参与者有A, B, C, 每次发起的事务都有一个全局唯一的id, 参与者之间的消息在网络故障时可以重发 (可以通过id去重复消息, 或者保证幂等操作). 假如T3在C中执行时失败了, 如果T3已经提交了或者这个系统不支持回滚, 那么必须使用C3来补偿T3带来的变化. 然后发消息给B, B会执行C2去补偿T2, 然后B可以选择继续通知A去回滚, 或者稍后等外部条件发生变化再执行T2, 然后让C去重试. 这样整个系统变成了一个状态机, 参与者之间虽然有可能不一致,一个订单或者一笔交易一定会处于状态机的某一个状态, 整个事务的过程仍然是整体可以追溯的.
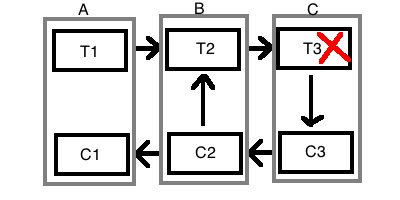
Saga这种方法并不适合所有的情况, 它也不是银弹, 但是它是比2PC/3PC更适合来解决分布式事务. 2PC/3PC的思路是想在源头上阻止分布式事务不一致的产生, 但这是不可能实现的. 不一致是常态, 不是异常, 异步网络中能容忍节点故障的total correct的consensus算法不存在.
大名鼎鼎的Paxos算法 1990 – 2001
Consensus主要目的是屏蔽掉故障节点的噪音让整个系统正常运行下去, 比如选举过程和状态机复制. 所以Consensus问题对于agreement条件做了放松, 它接受不一致是常态的事实, 既然我无法知道某些节点是挂了还是暂时联系不到, 那我只要关心正确响应的节点, 只要表决能过半即可, 过半表决意味着虽然没有完全一致, 但是”投票结果”被过半成员继承下来了, 这是因为任何两个quorum一定会存在交集(想象一下有A/B/C三个节点, 两个quorum比如AB和AC一定会有A是交集), 所以不管有多少个quorum存在, 我们能确保他们一定会有交集, 所以他们一定能信息互通而最终达成一致, 其他没有达成一致的成员将来在网络恢复后也可以和这部分交集内的节点传播出去的”真理”达成一致.
接下来我们会介绍一下大名鼎鼎的Paxos算法. Paxos是第一个正确实现适用于分布式系统的Consensus算法. 1990年Lamport提出了这个算法, 但有趣的是ACM TOCS的评审委员们没看懂他的论文, 主编建议他不要拿古希腊神话什么长老被砸健忘了的故事写论文, 要他用数学语言写简洁点, Lamport也是个人才, 他拒绝修改论文, 并在一次会议上公开质疑”为什么搞基础理论的人一点幽默感都没有呢?”. 6年光阴过去, 另外一个超级牛人, 图灵奖获得者Butler Lampson看到这篇论文, 而且…… 他看懂了! Lampson觉得这个算法很重要并呼吁大家重新审视这篇重要论文, 后来提出FLP理论的三人组其中的Nacy Lynch重写了篇文章阐述这篇论文, 后来终于大家都看懂了, 最终1998年ACM TOCS终于发表了这篇论文 “The Part-Time Parliament”[7], 至此将近9年了. 最爆笑得是1998发表的时候, 负责编辑的Keith配合Lamport的幽默写的注解, 这里我给八卦一下省的你去翻论文了:
本文最近刚被从一个文件柜里发现, 尽管这篇论文是很久之前提交的但是主编认为还是值得发表的(不是我们ACM TOCS过去没看懂, 是忘记发表了). 但是由于作者目前在希腊小岛上考古, ACM TOCS联系不上这位考古学家, 所以任命我来发表这篇论文(其实是Lamport拒绝修改论文, 不鸟ACM TOCS了). 作者貌似是个对计算机科学稍微有点兴趣的考古学家(赤裸裸的吐槽), 尽管他描述的Paxon岛上民主制度的故事对计算机科学家没啥兴趣, 但是但是这套制度对于在异步网络中实现分布式系统到时很好的模型(这句总算客观了). 建议阅读的时候直接看第四节(跳过前三节神话故事), 或者最好先别看(你可能会看不懂), 最好先去看看Lampson或者De Prisco对这篇论文的解释.
看到这你笑喷了没?
我们的”考古学家” Lamport在Paxos算法定义了三个角色, 其中proposer是提出建议值的进程, acceptor是决定是否接受建议的进程, learner是不会提议但是也要了解结果的进程, 在一个系统中一个进程经常同时扮演这三个角色. 算法分两个阶段 (以下是最基础的算法, 其中没有learners):
第一阶段: 一个proposer选择一个全局唯一的序号n发给至少过半的acceptors. 如果一个acceptor收到的请求中的序号n大于之前收到的建议, 那么这个acceptor返回proposer一个确认消息表示它不会再接受任何小于这个n的建议.
第二阶段: 如果proposer收到过半的acceptor的确认消息表示他们不会接受n以下的建议, 那么这个proposer给这些acceptor返回附带他的建议值v的确认消息. 如果一个acceptor收到这样的确认消息{n, v}, acceptor就会接受它. 除非在此期间acceptor又收到了一个更高的n的建议.
对证明有兴趣的读者可以去看看Paxos Made Simple. 简单来讲, 算法的正确性有两个方面
-
提议的safety是由sequence number N决定的, 如果N是全序集, 唯一而且一定有先后, 并且在每个proposer上都单调递增, 那么acceptor选择的结果就是安全的. 实际应用中, 这个N经常是timestamp, 进程id, 还有进程的本体counter的组合, 比如: timestamp + node id + counter, 或者像twitter的snowflake基于timestamp和网卡mac地址的算法. 这样可以保证事件顺序尽量接近物理时间的顺序, 同时保证事件number的唯一性. (注意,这个方法并非完美,因为如果有NTP同步时间,那么系统时间可能会变小导致n没有单调递增, 更好的做法是timestamp只启动时生成一次,后面只变counter, 或者有状态保存counter)
-
过半表决可以保证网络出现多个分区的时候, 任何两个能够过半的分区必然存在交集, 而交集内的进程就可以保证正确性被继承, 以后被传播出去.
Paxos是一个非常基础的算法, 更多的时候你需要在Paxos的基础之上实现你的算法.
Paxos的过半表决有一定局限性. 这牵扯到分区可用性. 如果网络分区的时候, 没有形成多数派, 比如一个网络内被均匀的分成了三个小区, 那么整个系统都不能正常工作了. 如果分成一个大区, 一个小区, 那么小区是无法工作的, 如果大区和小区非常接近, 比如是501 vs 499, 这意味着系统的处理能力可能会下降一半. 所有这些都影响到了Paxos的可用性. 举个例子, Zookeeper的ZAB协议的选举和广播部分很类似Paxos, Zookeeper允许读取过期数据来获得更好的性能, 所以一般情况下是Sequential Consistency. 但是他有一个Sync命令, 当你每次都Sync+Read的时候, 虽然性能大打折扣, 但是Zookeeper就是和Paxos一样能保证Linearizability了. 当zookeeper在发生网络分区的时候, 如果leader在quorum side (大区), 那么quorum side的读写都正常, 但是non-quorum side因为无法从小区选出leader, 所有连接到non-quorum side的客户端的所有的读写都会失败! (也可以不发Sync命令降低到SC级别, 通过过期的缓存让读操作能继续下去) 如果把client也考虑在内, 假设如下图所示, 99%的节点连同1%的客户端处于一个分区, 那么会导致99%的客户端都无法正常工作, 尽管这个时候集群是99%的节点都是好的. (通常我们的网络拓扑结构不会发生这么极端不平衡的情况).
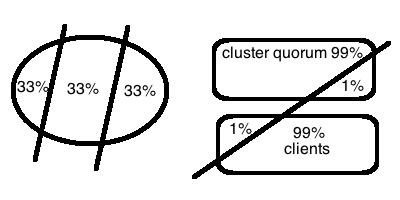
有人会觉得网络分区在同一个数据中心内发生的概率非常低吧? 其实不然, 举一个例子, github在2012年有一次升级一对聚合交换机的时候, 发现了一些问题决定降级, 降级过程中其中要关闭一台交换机的agent来收集故障信息, 导致90秒钟的网络分区, 精彩的开始了. 首先, github的文件服务器是基于DRBD的, 因为每一对文件服务器只能有一个活动节点, 另外一个作为热备, 当主节点出现故障后, 热备节点在接替故障的活动节点之前会发一个指令去关闭活动节点. 如果网络没有分区, 活动节点的硬件发生了故障导致响应超时, 那么这样可以避免brain-split. 但是在网络分区的情况下, 活动节点没有收到关闭指令, 热备节点就把自己作为新的活动节点了, 当网络恢复之后, 就有了两个活动节点同时服务, 导致了数据不一致不说, 还会发生互相尝试杀死对方的情况, 因为两边都认为对方是有故障的, 需要杀死对方, 结果有些文件服务器真的把对方都杀死了.
网络分区是真实存在的, 而且在跨多个数据中心的情况下, 网络分区发生的概率更高. 所以使用zookeeper的时候你一定要理解他的一致性模型在处理网络分区的情况时的局限性. 对于map reduce来讲, 结果是correct or nothing, 宁可牺牲可用性也要保证一致性, safety更重要. 但是一个分布式系统的服务发现组件就不同了, 对于发现服务而言, having something wrong is better than having nothing, liveness更重要. 所以Netflix的黑帮们才自己造了个轮子Eureka, 因为如果你的微服务都是无状态的, 大多数情况下发现服务只要能达到Eventual Consistency就可以了, 而高可用性是必须的. 后面介绍CAP定理和Eventual Consistency的时候会介绍一下侧重可用性的算法.
除了网络分区, Paxos的另外一个缺点是延迟比较高. 因为Paxos放松了liveness, 它有时候可能会多个回合才能决定结果, 错误的实现甚至会导致live lock. 比如proposer A提出n1, proposer B提出n2, 如果n1 > n2, acceptor先接受了n1, B收到拒绝之后重新发起n3, 如果n3先于A的确认消息到达acceptor, 而且n3 > n1, 那么acceptor会拒绝A, 接受B, A可能会重复B的行为, 然后无限循环下去.
FLP理论描述了Consensus可能会进入无限循环的情况, 但是实际应用中这个概率非常低, 大家都知道计算机科学是应用科学, 不是离散数学那样非正即误, 如果错误或者偏离的概率非常低, 工程中就会采用. 根据FLP理论, 异步网络中Paxos可能会进入无限循环. 真实世界中Paxos的如果两个节点不断的互相否定, 那么就会出现无限循环, 但是要永远持续下去的概率非常非常低, 实际中我们经常让某个Proposer获取一定期限的lease, 在此期限之内只有一个proposer接受客户端请求并提出 proposal. 或者随机改变n的增长节奏和proposer的发送节奏等, 来降低livelock的概率. 当然, 单从纯粹FLP理论来看, 超过一个proposer的时候Paxos是不保证liveness的.
Paxos在实现中, 每个进程其实一般都是身兼三职, 然后成功提议的那个proposer所在的进程就是 distinguished proposer, 也是 distinguished learner, 我们称之为 leader.
上面提到的Paxos算法是最原始的形式, 这个过程中有很多可以优化的地方, 比如如果accetpr拒绝了可以顺便返回当前最高的n, 减少算法重试的回合, 但这不影响这个算法的正确性. 比如Multi-Paxos可以假设leader没有挂掉或者过期之前不用每次都发出prepare请求, 直接发accept请求, 再比如Fast Paxos等等.
Paxos设计的时候把异步网络的不确定性考虑在内, 放松了liveness的要求, 算法按照crash-recovery的思想设计, 所以Paxos才可以成为这样实际广泛应用而且成功的算法. 但是Paxos也不能容忍拜占庭式故障节点, 要容忍拜占庭式故障实在是太困难了 (比如, Paxos中两个quorum中的交集如果都是叛徒怎么办?).
尽管Paxos有很多缺点, 但是Paxos仍然是分布式系统中最重要的一个算法, 比如它的一个重要用途就是 State Machine Replication. 一个Deterministic State Machine对于固定的输入序列一定会产生固定的结果, 不论重复执行多少次, 或者再另外一台一样的机器上执行, 结果都是一样的. 分布式系统中最常见的一个需求就是通过某种路由算法让客户端请求去一组状态一致的服务器, 数据在服务器上的分布要有replica来保证高可用性, 但是replica之间要一致. 状态复制就成为了分布式系统的一个核心问题. Paxos的状态复制可以保证整个系统的所有状态机接受同样的输入序列 (Atomic Broadcast), 如果查询也使用过半表决, 那么你一定会得到正确的结果.
这种做法相对于Master-Slave的的状态复制一致性好很多. 比如一旦Master节点挂了, 还没来得及复制的结果会导致Slave之间的状态有可能是不一致的, 如果客户端能够访问到延迟的Slave节点, 那么用户展现的数据将会不一致. 如果你可以牺牲性能来换得更高的一致性, 那么你可以通过Paxos表决查询来屏蔽掉延迟或者有故障的节点. 只要系统中存在一个quorum, 那么状态的一致性就可以保留下去. 比如google的chubby, 只要故障节点不超过一半, 网络没有发生分区, chubby就可以通过Paxos状态机为其他服务器提供分布式锁. 因为chubby分别部署在每个数据中心, 他们没有跨数据中心的通信, 所以网络分区的故障频率不像跨数据中心的情况那么多高, chubby牺牲部分性能和网络分区下的可用性, 换来了一致性.
因为Paxos家族的算法写性能都不是很好但是一致性又很重要, 所以实现中我们经常做一些取舍, 让Paxos只处理最关键的信息. 比如Kafka的每个Partition都有多个replicas, 日志的复制本身没有经过Paxos这样高延迟的算法, 但是为了保证负责接受producer请求和跟踪ISR的leader只有一个, Kafka依赖于Zookeeper的ZAB算法来选举leader. 在实际应用中, 状态机复制不太适合很高的吞吐量, 一般都是用于不太频繁写入的重要信息. Zookeeper不能被当做一个OLTP级的数据库用, 它不是分布式系统协同的万能钥匙.
Uniform Consensus
对于Consensus问题, 我们只关注非故障节点的一致性和整体系统的正常, 而Uniform Consensus中要求无论是非故障节点还是故障节点, 他们都要一致, 比如在分布式事务的前后, 各个节点必须一致, 故障节点恢复后也要一致, 任何时刻都不应该有两个参与者一个决定提交, 一个决定回滚. 很长一段时间内大多数人没有把Uniform Consensus单独分类, 直到2001年才有人提出Uniform Consensus更难[8].
一般的Consensus问题通常用来解决状态机复制时容错处理的问题, 比如Paxos, 而Uniform Consensus所处理的是分布式事务这样的问题, 在Uniform Consensus中我们要求所有节点在故障恢复后都要达成一致. 所以Uniform Consensus的定义在agreement上更加严格:
- termination: 所有进程最终会在有限步数中结束并选取一个值, 算法不会无尽执行下去.
- agreement: 所有进程(包含故障节点恢复后)必须同意同一个值. (假设系统没有拜占庭故障)
- validity: 最终达成一致的值必须是V1到Vn其中一个, 如果所有初始值都是vx, 那么最终结果也必须是vx.
小结
至此, 通过对Concensus问题的介绍, 我们对Linearizability和Sequential Consistency的应用应该有了更深入的理解, 在本系列下一篇文章中我们将会介绍性能更好但是一致性要求更低的Causal Consistency, PRAM以及不需要硬件自动同步的一致性模型, 比如Weak Consistency. 敬请期待. 文中的错误请通过电子邮箱daniel.y.woo@gmail.com发送给我, 因为微信不能更新已经发布的文章, 所以我会在danielw.cn更新.
参考
- Miguel Castro and Barbara Liskov. “Practical Byzantine Fault Tolerance” Proceedings of the Third Symposium on Operating Systems Design and Implementation, New Orleans, USA, February 1999
- Jim Gray. “Notes on data base operating systems” In Operating Systems: An Advanced Course, R. Bayer, R. M. Graham, and G. Seegmuller, Eds. Lecture Notes in Comp
- Dale Skeen. “Nonblocking commit protocols” SIGMOD ‘81 Proceedings of the 1981 ACM SIGMOD international conference on Management of data
- E. A. Akkoyunlu, K. Ekanadham, R. V. Huber. “Some constraints and tradeoffs in the design of network communications” SOSP ‘75 Proceedings of the fifth ACM symposium on Operating systems principles
- Leslie Lamport, Robert Shostak, Marshall Pease. “The Byzantine Generals Problem” ACM Transactions on Programming Languages and Systems (TOPLAS), Volume 4 Issue 3, July 1982
- Michael J. Fischer, Nancy A. Lynch, Michael S. Paterson. “Impossibility of Distributed Consensus with One Faulty Process” Journal of the Association for Computing Machinery, Vol. 32, No. 2, April 1985
- Leslie Lamport. “The Part-Time Parliament” ACM Transactions on Computer Systems 16, 2 (May 1998), 133-169
- Bernadette Charron-Bost, André Schipe. “Uniform Consensus is Harder Than Consensus” Journal of Algorithms Volume 51 Issue 1, April 2004