数据库和缓存的一致性
前言
此文为之前发布的Cache Consistency with Database的中文版.
Cache consistency and coherency 是计算机科学中非常困难的两个话题,本文我们只讲述一种情况,就是我们使用数据库和缓存的时候,缓存和数据库内容的一致性。比如Redis+MySQL的模式,这可能是目前最为普遍的一种设计方式。
概念
在我们开始之前,我们现需要重温一下各种常用的缓存模式。
缓存模式
Write & Read
-
Write Through: 同步写入数据库,然后缓存。这种模式下,数据写入是安全的不会丢失挥发的。但是这种模式比较慢,因为下层的数据库通常比缓存慢很多。
-
Write Behind (or write back): 先写缓存,然后立即返回成功,后台异步写入数据库。这种模式写肯定非常快,对数据库的压力也比较平缓,而且异步写入的时候可以合并多次写入变成一次写入,进一步减少对数据库的压力。但是这种模式下数据库和缓存之间不一致的时间窗口比较大,而且一旦缓存服务器重启,还没来得及flush进入数据库的数据有可能丢失。RAID card 为例,为了避免服务器掉电丢失缓存中的数据,我们通常会使用BBU备用电池来确保没有落盘的数据不会因为掉电而丢失。
-
Write invalidate: 类似于write-through, 先写入数据库,然后清除缓存,而不是更新缓存。这种模式部分解决了了并发写入的时候,数据库和缓存之间的不一致, 并且不需要引入分布式锁,实现比较简单。缺点就是你的hit rate会比较低,因为你总是invalidate缓存, 这经常会导致下一个read读不到缓存。
-
Refresh Ahead: 可以预测热数据并自动从数据库刷新高速缓存,从不block read,通常用于小型只读数据集,例如,邮政编码列表缓存,由于它很小且是只读的,因此可以定期刷新整个缓存。对于可写的大数据集合,如果你可以预测最常读取哪些键,那么你也可以使用这个方式来预热缓存。最后一种情况是,如果缓存数据是被外部系统更新的,而且你还得不到通知,你可能只能用这个模式来更新缓存了。
-
Read Through: 当读不到缓存,从数据库加载并更新到缓存。这种模式通常和写的三种模式配合使用。这种模式的缺点是你需要配合refresh ahead预热数据,否则每个key第一次读取的时候都会很慢。在市场活动的峰值流量到来之前,通常你要预热缓存, 防止冷缓存击穿数据库。
在大多数情况下,我们将read-through和write-through/write-behind/write-invalidate一起配合使用。Refresh-ahead可以单独使用,也可以作为read-through的补充优化。
Responsibility
缓存从数据操作职责范围来看,有两种实现模式。
-
cache-through: (or look-through, or inline-cache) 缓存层是一个类库或服务委托写到数据库,而您的应用仅与缓存层对话,缓存层负责对数据库的读写,确保缓存和数据库的一致性和故障转移。例如,许多数据库都有自己的内部缓存,所有的操作都要经过这个缓存,调用者不必关心缓存的更新和过期,缓存和磁盘的一致性是有保障的。这是cache-through的一个很好的例子。另外一个例子是Spring的cache annotation。您还可以编写一些进程内DAO层来读取/写入具有嵌入式缓存层的实体,从调用者的角度来看,这个很小的层也是一个cache-through, 比如Spring的cache实现(@Cacheable and @CachePut),但是这时候缓存一致性就无法保证了。
-
cache-aside: (or look-aside) 您的应用程序同时感知cache和数据库的存在,需要自己来维持缓存,这意味着您的应用程序代码更加复杂,但是这提供了更大的灵活性。比如,cache-aside模式下更容易细粒度的禁止某些数据缓存,或者通过检查数据来动态设定TTL,甚至对于某些一致性要求比较高的请求跳过缓存,可以缓存多条数据库记录计算出来的对象而非最原始的多条数据库记录。尽管有这些优点,但是这种模式下开发人员需要写更多的代码,框架无法全自动化。另外,cache-aside模式下通常缓存一致性比较难保持,无法做到数据库内置的缓存所能达到的一致性。
无论采用哪种模式,您都必须面对和解决并发一致性,而这在分布式系统中通常很困难,并且常常被遗漏。由于无论是cache-through 还是 cache-aside, 我们都需要解决一致性并且实现方式相同,因此在本文中,我将只以 cache-aside 模式讨论此主题.
什么是一致性(Consistency)
首先,我们先定义什么是缓存一致性。关于分布式系统一致性问题的基本讨论,请参考分布式系统一致性的发展历史.
对于缓存一致性 一种是底层资源和缓存之间的一致性,the cache-database consistency, 还有一种是使用缓存的应用节点之间的一致性: client-view consistency.
Cache-database Consistency
这是缓存和资源(通常是数据库)之间的一致性。由于它们是两个独立的系统,因此更改任何数据时总会出现不一致的时间窗口。如果第一个操作成功而第二个操作失败,则会产生许多问题。对于write-through,您首先更改数据库,然后缓存和数据库会有个很小的窗口不一致。对于write-behind,您首先要更改缓存,因此数据库会有一个短暂时间和缓存不一致。(不一致的窗口大小对于write-behind模式很重要,因为不一致的时间窗口意味着在高速缓存系统发生故障时数据丢失的可能性, 而过小的窗口又无法体现cache behind的性能优势)。基本上,它们之间总是存在不一致的地方,我们所能做的就是最小化不一致的时间窗口。
通常,在非分布式系统(如MySQL中的查询缓存)中的cache-through模式更易于实现,因为对磁盘的写入和缓存都是本地的。但是MySQL的查询缓存性能不佳,有两个原因。首先,很难识别受影响的查询,因为MySQL支持复杂的查询(您可以join很多表或使用它做很多复杂的事情,比如子查询)。假设您有一个包含100行的表,并且您有100条查询来查询每行。如果更新一行,则将evict所有其他99个缓存查询,此处缓存的好处很小。另一个原因是MySQL缓存需要提供MVCC和linearizability级别的一致性,这会使cache evict更加频繁。由于这两个原因,MySQL必须选择一种粗粒度的方法来到期并evict cache。这就是为什么我们经常使用Redis作为cache aside模式来牺牲一致性以获得更好的性能。像Cassandra这样的NoSQL数据库没有这样的问题,因为它没有提供如此强的一致性保证,并且支持更简单和可预测的查询。 Cassandra具有memtable作为write-behind缓存层,因此写入速度非常快, 这是特别好的一个cache-through模式的实现。同时为了避免由于write-behind造成的数据丢失,它具有WAL和in-memory副本以确保数据安全。因此,您不需要额外的Redis缓存层(cache-aside)即可与Cassandra一起使用。
Client-view Consistency
这意味着每个客户端都具有缓存数据的一致视图。在许多情况下,这对于正确的应用程序行为很重要。如果数据从版本1更新到版本2, 3,…到5,任何客户端应该看到相同的顺序(total order),不应该有任何一个客户看到1-2-5-3-4。这实际上是分布式系统中的顺序一致性模型(sequential consistency model)。(有关更多详细信息,您可以通过Google搜索sequential consistency或阅读我的系列文章分布式系统中的一致性模型的历史。
有时您不关心完整的历史记录,而仅关心最新的更新,在这种情况下,如果客户能够看到1-2-3-4-5但决定丢弃2-3并获得视图1-4-5,也可以。
Sequential Consistency模型没有任何延迟要求,如果客户端看到1-2-3-4-5,但要花很长时间才能看到1到2,这是符合这个模型的。但是,实际工程中有时我们希望每个客户总是立即看到最新的更新,即线性化一致性模型(Linearizability Consistency Model),加了延迟要求之后,这是一个非常严格的一致性模型,通常很难实现。
在本文中,我们讨论了如何在客户端视图之间实现顺序一致性,并尝试最小化延迟。现在,您已经掌握了有关缓存系统中一致性问题的基本概念,恭喜您热身完毕,下面我们来看一些具体工程中的缓存一致性问题。
一致性问题
Client/Network Failure in Write-through
下图是Write-through。在T2读取X的同时T1尝试更新X。如果在第2步T1崩溃或网络中断,该怎么办? T2将在第3步之后始终看到陈旧的数据,直到缓存过期。这符合顺序一致性模型,在某些情况下如果应用对延迟不敏感,或者缓存的过期时间设置比较短,这可能不是一个大问题。
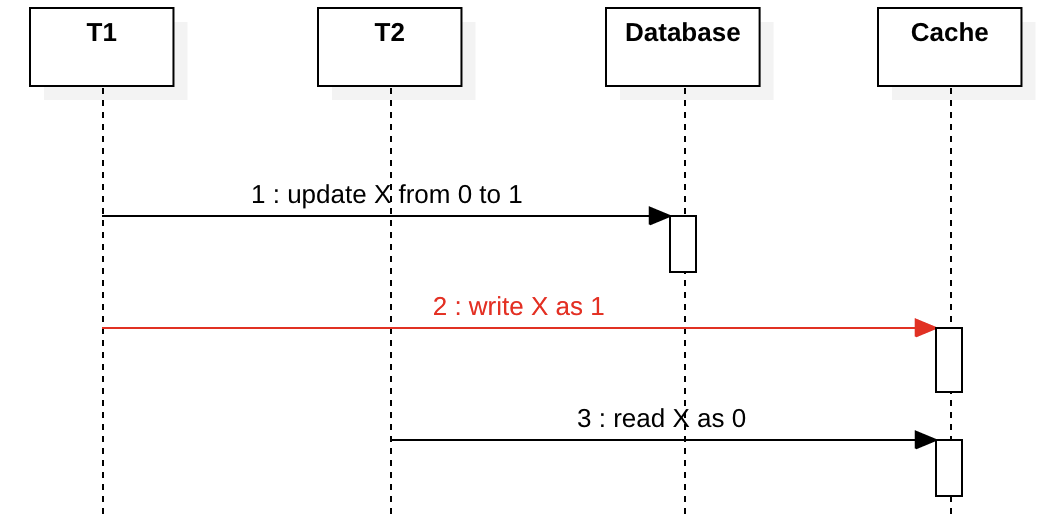
在这种情况下,真正的大问题是Cache Evict。如果Cache Evict基于LRU并且频繁读取数据,则缓存数据库不一致时间窗口将很大,甚至是无限的,这意味着T2将永远不会看到新值,这不满足client view之间的任何一致性模型,并会在您的应用程序中引起严重的问题。为避免这种情况,需要根据首次写入缓存时的时间戳强行设置一个固定的到期时间(例如Caffeine中的expireAfterWrite).
Concurrency in Read-through
假设我们不使用分布式锁来协调T1和T2,X在缓存中一开始不存在。下图显示T1和T2都遇到缓存未命中。在第3步之后,如果在T1中发生诸如JVM full GC之类的事件,会导致其对数据库的更新延迟。同时,T2会先于T1更新缓存并将X写入最新值2,最终T1从GC恢复并将其过时的值1写入缓存。如果T2再次读取X,它将看到一个旧值,并且可能会感到困惑。这种情况下,顺序性(Sequential Consistency)和线性化(Linearizability Consistency)一致性均不能满足。
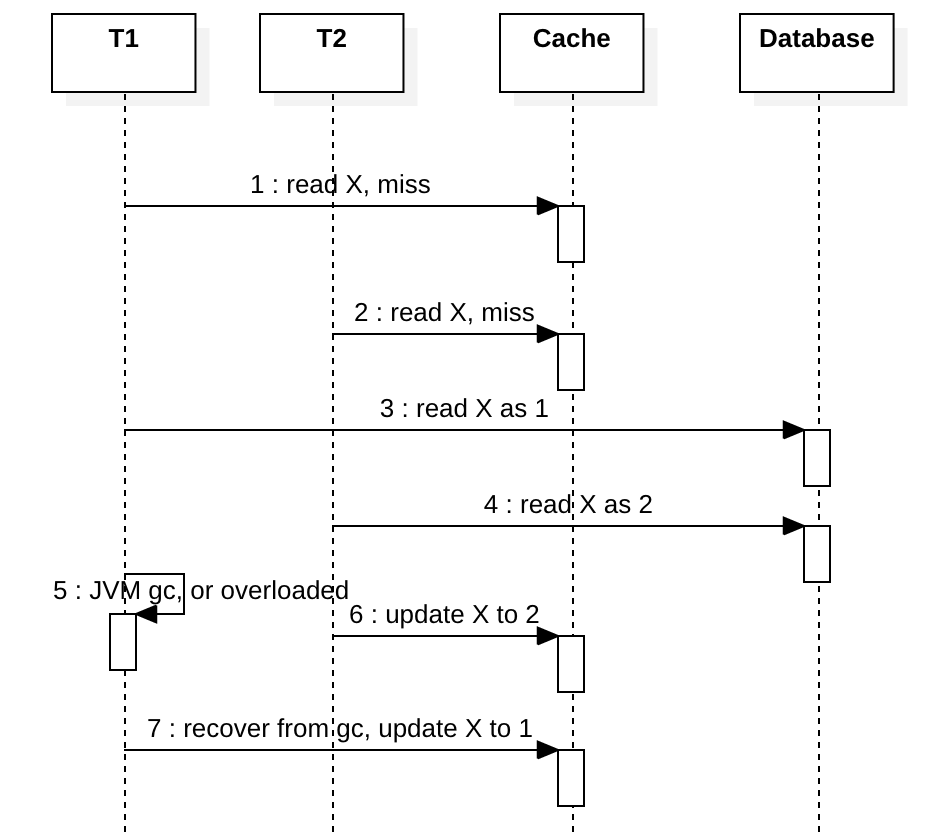
使用分布式锁可以解决此问题,但这太昂贵了。一个简单的解决方案是防止CAS在步骤7中T1写陈旧数据。大多数现代的缓存系统都支持CAS写入(例如Redis Lua),我们可以在以下版本列上使用CAS写入, 以下为Lua脚本的实现:
# Arguments
#KEYS[1]: the key
#ARGV[1]: old version
#ARGV[2]: new version
#ARGV[3]: new value
#ARGV[4]: TTL in seconds
# You can test in redis-cli:
eval "local v = redis.call('GET', KEYS[1]); if (v) then local version, value = v:match(\"([^:]+):([^:]+)\"); if (version ~= ARGV[1]) then return 1; end end redis.call('SET', KEYS[1], ARGV[2] .. ':' .. ARGV[3], 'EX', tonumber(ARGV[4])); return 0;" 1 key1 0 1 value1 1000
使用CAS,在步骤7中,T1的写入将失败,并且T1能够retry再次查询缓存以获取最新的X。
一个非常特殊的情况是,如果T1暂停很长时间,足够长以至于在步骤6中写入的X值到期,那么T1仍然能够将过时的数据写入缓存,但是这种情况很少发生,因为T1必须暂停很长的时间,可能是15分钟,这不太可能发生。因此,这只是理论上的一种可能性。如果要解决此问题,请考虑在写入缓存时带上时间戳,并且在CAS操作的同时检测时间戳,如果缓存带上的时间戳太旧,则缓存系统可以拒绝该写入。例如,到期时间设置为5分钟,如果写入的时间戳早于5分钟,则拒绝并报告错误,以便客户端可以意识到这一点并重试。但是,任何基于时间戳的解决方案都容易受到时钟漂移的影响,因此您必须具有正确的NTP设置。
Concurrency in Write-through
假设我们不使用分布式锁来协调T1和T2,T1和T2都尝试更新X。
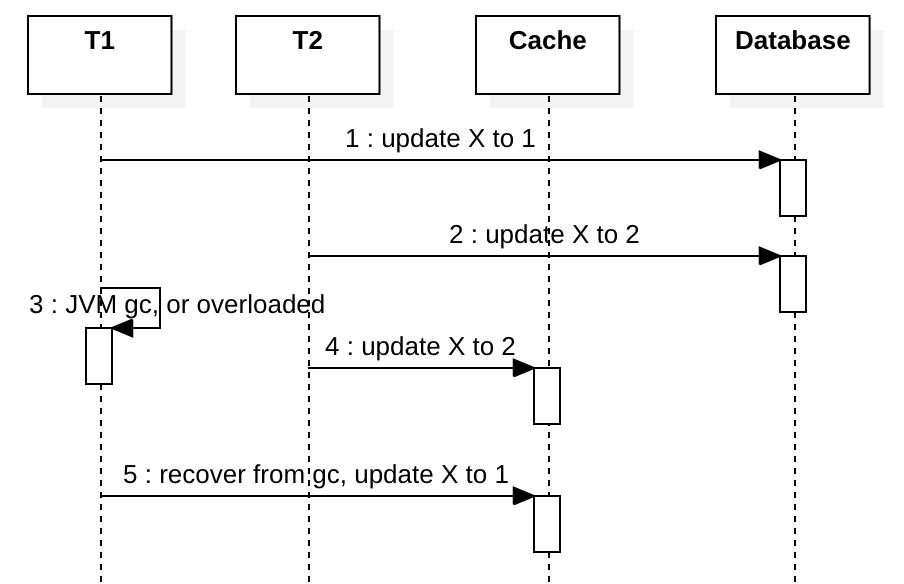
理想情况下,在步骤2之后,T1应该将缓存更新为1,但是如果在T1中发生类似JVM full GC的事情,而T2更新缓存并将X写入最新值2,则T1稍后会将其过时的值1写入X中。这与前面提到的并发问题类似,但是发生的可能性更高,它不需要两个并发的高速缓存未命中(这种情况相对少见)。
要在没有分布式锁的情况下解决此类问题,可以将写入write-invalidate与read-through结合使用。在步骤4/5中,我们只是使缓存键无效,并且下一次读取应重新创建缓存的数据。这样,T1 / T2在下一次读取中都将X视为2,如果另一个T3在步骤4和5之间读取X,则它将看到高速缓存未命中并尝试从数据库加载高速缓存,并且将X视为2。现在我们达到线性化一致性(Linearizability)水平。缺点很明显,在先写后读的情况下,命中率很低。
您还可以使用前面的例子中的CAS加版本方式写入来确保顺序。每次更新数据库时,您都增加并取回这条记录的版本,然后仅在写请求里的数据版本高于缓存里数据版本时才更新缓存。这样可以防止发生第5步。除非T1暂停很长时间并且X过期(这种情况很少见),否则它在大多数情况下都应该起作用。该解决方案有点复杂,只有在您真正需要它时才使用它。
Concurrency in Write-Invalidate
为了解决write-through中的问题,我们可以使用write-invalidate模式。如果在刚才writre-through的时序图中将“ update X to …”更改为“ invalidate cache”,则它看起来像这样:
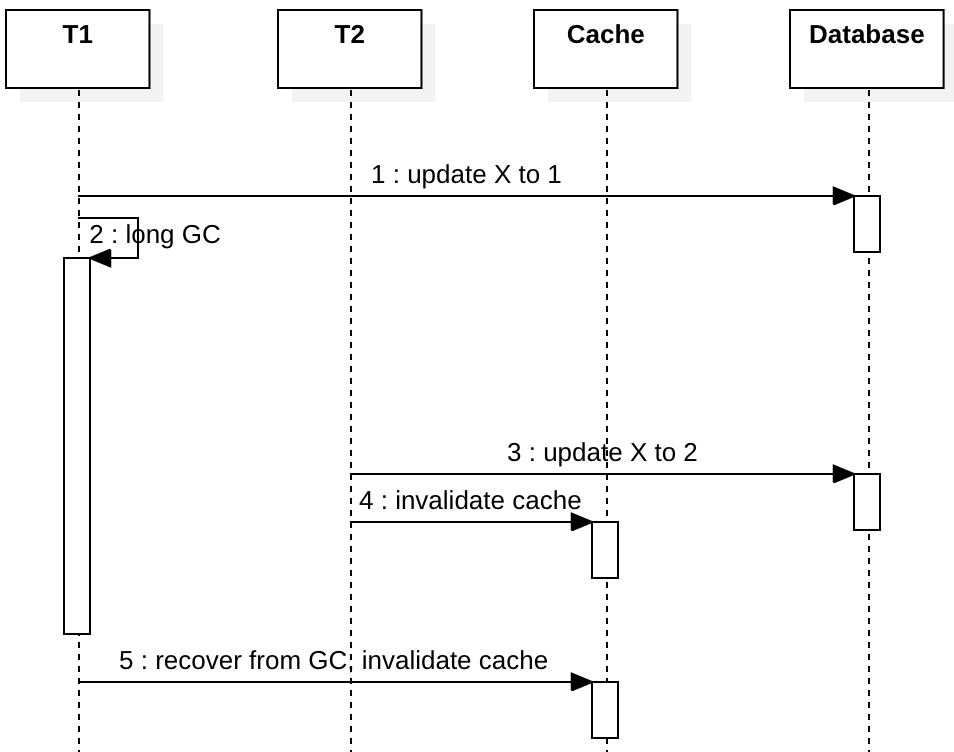
然后,任何后续读取都会看到缓存未命中,并使用最新值重新填充缓存。但是,这只能解决两个写客户端之间的某些数据争用方案,不能解决一个读取客户端和一个写客户端之间的数据竞争问题,它只是尽力而为的最终一致性,而不是顺序一致性。我将在下一节中解释原因。在此之前,让我们介绍一下Facebook如何通过锁定(租赁)解决此问题。
Facebook在2013年发表了一篇论文,解释了Write-Invalidate模式与“lease”(实际上是悲观锁)一起使用的方式。摘自 Scaling Memcache at Facebook 3.2.1.
Intuitively, a memcached instance gives a lease to a client to set data back into the cache when that client experiences a cache miss. The lease is a 64-bit token bound to the specific key the client originally requested. The client provides the lease token when setting the value in the cache. With the lease token, memcached can verify and determine whether the data should be stored and thus arbitrate concurrent writes. Verification can fail if memcached has invalidated the lease token due to receiving a delete request for that item. Leases prevent stale sets in a manner similar to how load-link/storeconditional operates [20].
假设T1和T2都去更新数据,悲观锁下只有一个client可以写数据库和缓存. 比如,
T1 gets the lease
T2 fails to get the lease, wait
T1 updates and commits database
T1 returns the lease
T2 kicks in
这篇论文没有说明在发生错误的情况下如何退还lease(lock),但是各种异常情况下我们还是可以获得 sequential consistency。但是明显悲观锁的生命周期很长,尤其是数据库更新慢的时候。对于大并发写入吞吐会下降。我相信CAS+versioning是比他更好的解决方案,尤其是考虑到吞吐性能。好了,现在让我们看看没有锁的情况下为什么很难通过并发客户端和具有写入无效和通读功能的服务器来实现顺序一致性
Concurrency with Write-Invalidate and Read-through
在上一节中,我们讨论了write-invalidate如何解决由write-through引起的问题。但是,将write-invalidate与read-through一起使用时也存在问题,这是许多系统中非常常见的模式。假设我们不使用分布式锁来协调T1和T2,T1都尝试读取X,T2都尝试更新X。
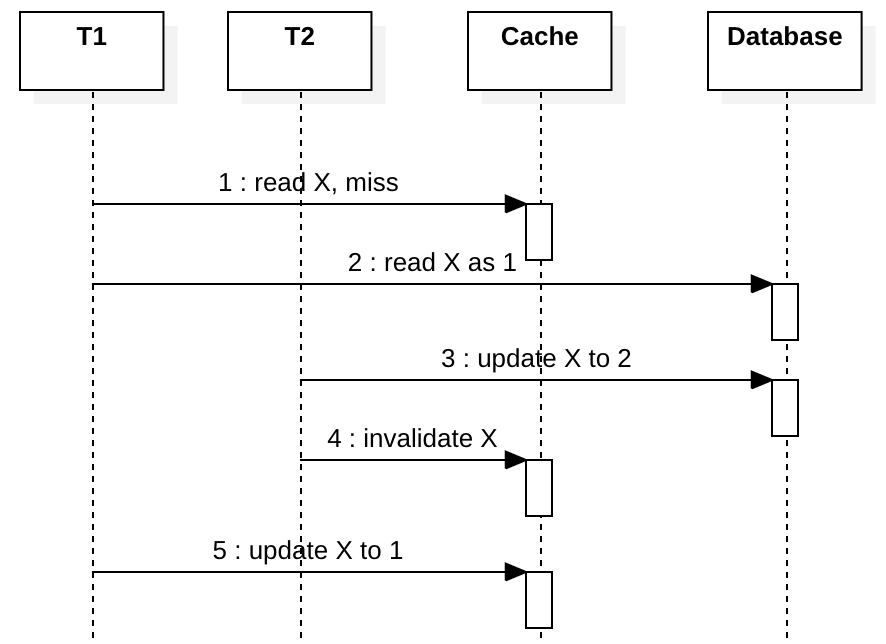
如上图所示,如果T1过载并且由于某种原因它很慢,则本应在第2步完成后就执行的操作,可能被延迟到第5步并将过时的值写入缓存。
CAS写入解决方案不适用于写入Write-invalidate,因为一旦在步骤4中删除了缓存的key,没了key您就无法通过CAS进行比较。
某些人使用类似write-deferred-invalidate解决方案的方法,即第3步写入后,立即返回,并且在后台启动一个异步任务安排500ms之后清除这个缓存。这个想法是希望我们可以预测T1的滞后时间不超过500ms,使用异步任务在步骤5之后清除掉缓存。
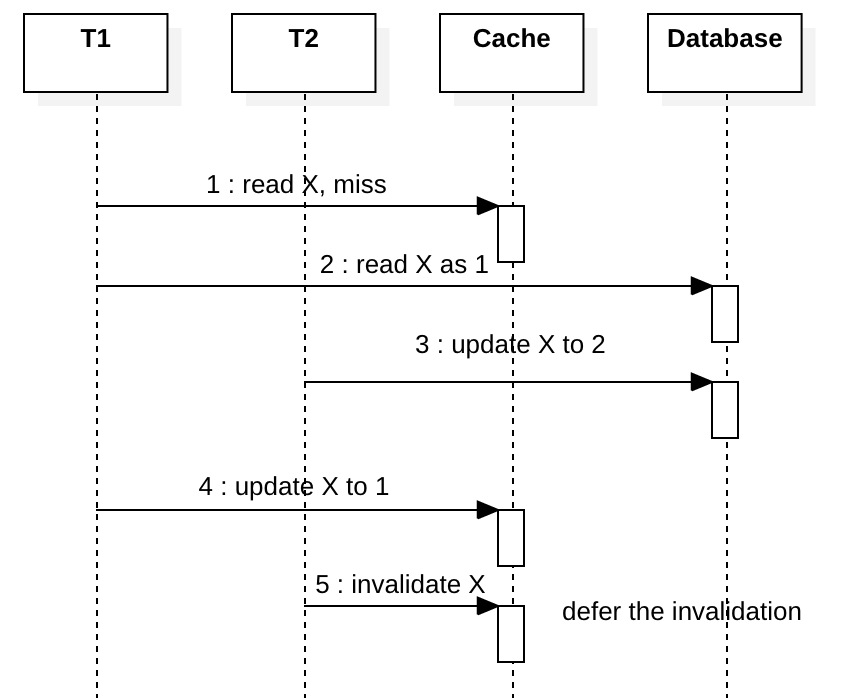
这方案还有一个好处,就是当您拥有一组只读的slave database时,此解决方案还有助于隐藏数据库master-slave服务器之间的延迟。如果T1更新master数据库,T2从slave数据库实例读取,T2将看不到T1所做的最新更改,因此T2可以填充陈旧的数据到cache,并且500ms之后T1会删除掉T2写入到陈旧的高速缓存。
但是这种解决方案也有许多缺点。首先,在更新缓存中的现有值的情况下,新值始终会以500ms的延迟消失,这会大大降低缓存命中率。此外,这个方案的效果取决于延迟的正确设置,其实延迟是通常无法预测的,因为延迟会随负载,硬件变化等而变化。所以我不建议write-deferred-invalidate,预测延迟只是赌博而已。
总之,这个问题除了CAS没有一个非常好的解决方案。
其它方案
双删模式
这种模式其实是write-through的变体形式,起源于一些工程师,他们希望首先使缓存无效,然后再写入数据库。这是一个三步解决方案:1)使缓存无效。 2)写入数据库 3)异步延迟删除缓存。我不明白为什么他们要在写入数据库之前使缓存无效,这只会导致更多的不一致。而且三步解决方案非常昂贵。实际上,这基本上就是我们在上一节中讨论的 write-deferred-invalidate 解决方案。我不会推荐这个方案。
MySQL binlog to Cache
这是阿里巴巴工程师的解决方案。他们有一个侦听器,用于接收MySQL Binlog并在Redis或其他类型的缓存中填充缓存的数据。这样,您就不再需要在应用程序代码中编写缓存,监听器会自动填充缓存。而且您有从属数据库实例滞后,因此您不需要延迟缓存失效。听起来很酷,这个方法符合Sequential Consistency模型。但是该解决方案对缓存处理的粒度很粗糙,比如你有100张表,只需要缓存一张表,你仍然需要处理所有的binlog并丢弃99张表相关的日志,只处理1%的日志。另外这个方案延迟会高一点,因为你需要异步复制和解析binlog。这个方案的一个很大的优点是,在多地多活的数据复制的基础上可以实现缓存自动同步。不过要小心一定是数据库先写,后写cache,一旦binlog写入数据库有故障导致中断,cache这时候也不能写了,否则volatile cache的数据比non-volatile的数据库新会造成数据幻读。这时候你的数据一致性只能达到Eventual Consistency Level,无法达到Sequential Consistency。 对于更复杂情况,比如每个数据中心如果既有复制也有本地应用一起写缓存的情况,不在本文讨论范围之内,这个情况非常复杂,有兴趣的同学具体可以看facebook这篇论文的“Across Regions: Consistency”部分如何使用“remote marker”来解决缓存一致性问题。 但如果没有大规模跨数据中心多数据库复制的场景,我也不太推荐这个方案。
故障考虑
如果对缓存的更新失败,read-through不会带来任何问题,除了增加数据库负载。如果对缓存的更新因在write-through或者write-invalidate的时候失败,则在另一个成功的写入缓存或者缓存到期之前,您将看不到最新值。当您将所有这些缓存模式组合在一起使用时,事情变得很复杂。
结论
考虑到各种错误和故障,使用分布式缓存和数据库系统来实现Linearizability Consistency模型通常是不可能的。每个缓存模式都有其局限性,在某些情况下,您无法获得Sequential Consistency,或者有时您会在缓存和数据库之间获得意外的延迟。在我在本文中展示的所有解决方案中,总是会遇到一些高并发情况。因此,在选择解决方案之前,没有万灵药,要先了解限制并定义一致性要求。如果你需要Linerizability级别的一致性,并且在缓存写入失败的情况下也要保持这个级别的一致性,恐怕你最好放弃使用缓存。通常来说可以使用缓存的场景一定是对一致性要求有所松动的场景。
在不考虑超长GC或者超长故障的情况下,read-through和write-through配合CAS版本,可以解决大多数情况下Sequential Consistency的要求。但是CAS版本的实现稍微复杂一些。如果一致性要求更低,那么Write-Invalidate and Read-through也是可以的。