Cache Consistency with Database
Overview
Cache consistency and coherency is one of the most difficult problems in computer science and it’s a very big topic. In this article, we only talk about layered cache like Redis on top of a database, which is commonly used nowadays. But the generality exists among all cache applications.
Concepts
Before we start, let’s go through the commonly used cache patterns by how we refresh the cache.
Cache Patterns
Write & Read
-
Write Through: Synchronously write to the database then cache. This is safe because it writes to the database first, but it’s slower than Write-Behind. It offers better performance for write-then-read scenarios than write-invalidate.
-
Write Behind (or write back): write to the cache first, then asynchronously write to the database. This is fast for writing, and even faster if you combine multiple writes on the same key into a single write to the database. But the database is inconsistent with the cache for a long period of time, and you could lose data in case the process crashes before the data is flushed to the database. A RAID card is a good example of this pattern, to avoid data loss you often need a battery backup unit on a RAID card to hold the data in the cache but not landed to disk yet.
-
Write invalidate: similar to write-through, write to the database first, but then invalidate the cache. This simplifies handling consistency between cache and database in case of concurrent updates. You don’t need complex synchronization, the trade-off is hit rate is lower because you always invalidate the cache and the next read will always be a miss.
-
Refresh ahead: predict hot data and automatically refresh cache from the database, never blocking reads, best for small read-only dataset, For example, zip code list cache, you can periodically refresh the whole cache since it’s small and read-only. If you can precisely predict what keys to be read most, you can also warm up those keys in this pattern. Lastly, if the data is updated outside of your system and your system can’t be notified, you probably have to use this pattern.
-
Read Through: When a read misses, load it from the database and save it to the cache. The major problem of this pattern is that sometimes you need to warm up your cache (with refresh ahead pattern), if you have a hot product on sale exactly at 9:00 AM on black Friday on your website, a cold cache could cause many requests pending for that product.
In most cases, we use read-through with write-through/write-behind/write-invalidate. Refresh-ahead can be used standalone, or as an optimization to predict and warm-up reads for read-through.
Responsibility
And there are two implementation patterns by the scope of the responsibility of the application.
-
Cache-through: (or look-through, or inline-cache) The cache layer is a library or service delegates write to the database and your application only talks to the cache layer. The cache layer can handle the database under the hood, and ensure consistency and failover. For example, many databases have built-in cache, everything goes through the cache then disk, the client application is not aware of the consistency between cache and disk, this is a good example of cache-through. Another example is the abstract cache layer in a Spring application, from the callers’ perspective this layer is also a cache-through pattern. (See @Cacheable and @CachePut annotations in Spring cache framework).
-
Cache-aside: (or look-aside) Your application maintains cache consistency that means your application code is more complicated, but this allows more flexibility. For example, developers can prevent some data from being cached, or set TTL dynamically by inspecting the data content, bypass cache for some queries with high consisntecy requirements, cache composite object instead of caching raw database records. Despite the benefits, the trade-off is more coding since they cannot happen automaitcally under the cache framework. And it’s also difficult to keep the cache consistent like cache-through, e.g., since all queries go through the built-in cache of a database, so the cache consistency is easier to implement.
The cache-through and cache-aside patterns are distinguished from the caller’s perspective. No matter which pattern you go, you always have to deal with concurrency and consistency that is difficult and often omitted in a distributed system. Since it has to be solved either in cache-aside or cache-through pattern, and the implementation is actually the same, so I’ll talk about this topic under cache-aside pattern throughout this article.
Consistency
Now, let’s define our consistency problems. (For more details about consistency models, please refer to 分布式系统一致性的发展历史, sorry it’s only available in Chinese currently).
We have two kinds of consistency problems here, cache-database consistency and client-view consistency.
Cache-database Consistency
It is the consistency between cache and database. Because they’re two independent systems, there is always an inconsistent time window when you change any data. If the first operation succeeds and the second one fails, it creates many problems. For Write-through, you change the database first, then the cache is inconsistent. For Write-behind, you change the cache first, so the database is inconsistent. The inconsistency matters for the write-behind pattern since the inconsistent time window means the probability of data loss if the cache system fails. Basically, there is always inconsistency between them, all we can do is to minimize the time window of the inconsistency. In general, a cache-through pattern in a non-distributed system like the query cache in MySQL is easier to implement since both the write to disk and cache are local. But MySQL’s query cache is not very performant for two reasons. First, it’s difficult to identify affected queries because MySQL supports complex queries (you can join tables or do a lot of complex things with it, for the same reason sub-query is not cached). Suppose you have a table with 100 rows, and you have 100 queries to query each of them. If one row is updated, all other 99 cached queries are evicted and the benefit of cache here is little. Another reason is that MySQL cache needs to provide MVCC and linearizability level consistency which makes cache eviction more frequent. Due to the two reasons, MySQL has to choose a coarse-grained method to expire and evict cache. That’s why we often use Redis as a cache-aside pattern to trade off consistency for better performance. NoSQL databases like Cassandra do not have such problem because it does not provide such strong consistency guarantee and it supports much simpler and predictable queries. Cassandra has memtable as write-behind cache layer, so writing it extremely fast. To avoid data loss due to the write-behind pattern, it has WAL (write-ahead log) and in-memory replica to ensure data safety. So you don’t need an extra Redis cache layer to work with Cassandra.
Client-view Consistency
It means that each client has a consistent view of the cached data. It is important for correct application behaviors in many cases. If the data is updated from version 1 to 2, 3, … to 5, any client should see the same total order but none of them sees something like 1-2-5-3-4. This is actually the sequential consistency model in a distributed system. (for more details, you can google sequential consistency or read a series of my article History of consistency models in distributed systems (Chinese version only for now, I will write an English version later).
Sometimes you don’t care about the full history, only care about the latest update is visible, in that case, if a client is able to see 1-2-3-4-5 but decides to drop 2-3 and get a view of 1-4-5, that’s fine either.
Sequential consistency does not enforce any latency requirement, if a client sees 1-2-3-4-5 but it takes a long time to see 2 after 1, it’s OK. However, sometimes we want each client to always see the most recent update immediately, that is the linearizability consistency model and it’s a very strict consistency model, often difficult to implement.
In this article, we discuss how to implement sequential consistency among client views and try to minimize the latency. Now, you have the basic concept about consistency problems in cache systems, now let’s show some consistency problems.
Consistency Issues
Client/Network Failure in Write-through
The diagram below is a write-through pattern. T1 tries to update X meanwhile T2 reads X. What if T1 crashes or its network is broken at step 2? T2 will always see stale data at step 3 until the cache expires. This complies with the sequential consistency model, depends on your actual use cases, the latency is probably not a big problem if cache expiration time is short enough.
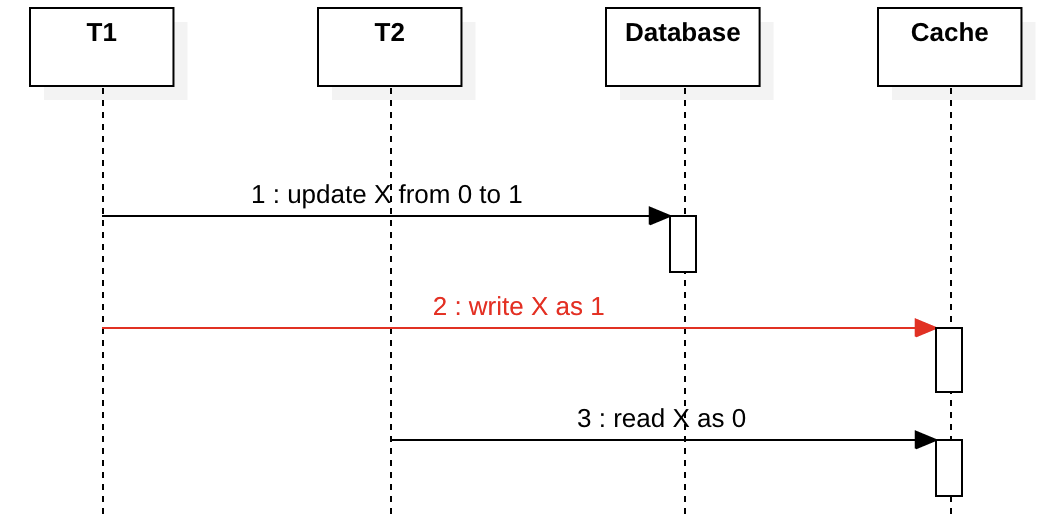
The real problem in this case is cache eviction. If the cache eviction is based on LRU and the data is frequently read, the cache-database inconsistency time window will be large, even infinite, that means T2 will never see the new value, this does not satisfy any consistency model among the client views and will cause severe problems in your application. To avoid this, force a fixed expiration time based on the timestamp when the key is first cached (e.g. expireAfterWrite in Caffeine).
Concurrency in Read-through
Suppose we don’t use a distributed lock to coordinate T1 and T2, X does not exist in cache yet. The diagram below shows both T1 and T2 encounter a cache miss. After step 3, if something like a JVM full GC happens in T1, the updates to the database will be deferred. Meanwhile, T2 updates the cache and writes X to the latest value 2, eventually T1 recovers from GC and writes its stale value 1 to cache. If T2 reads X again, it sees an old value and might be confused. Both sequential and linearizability consistency are not satisfied.
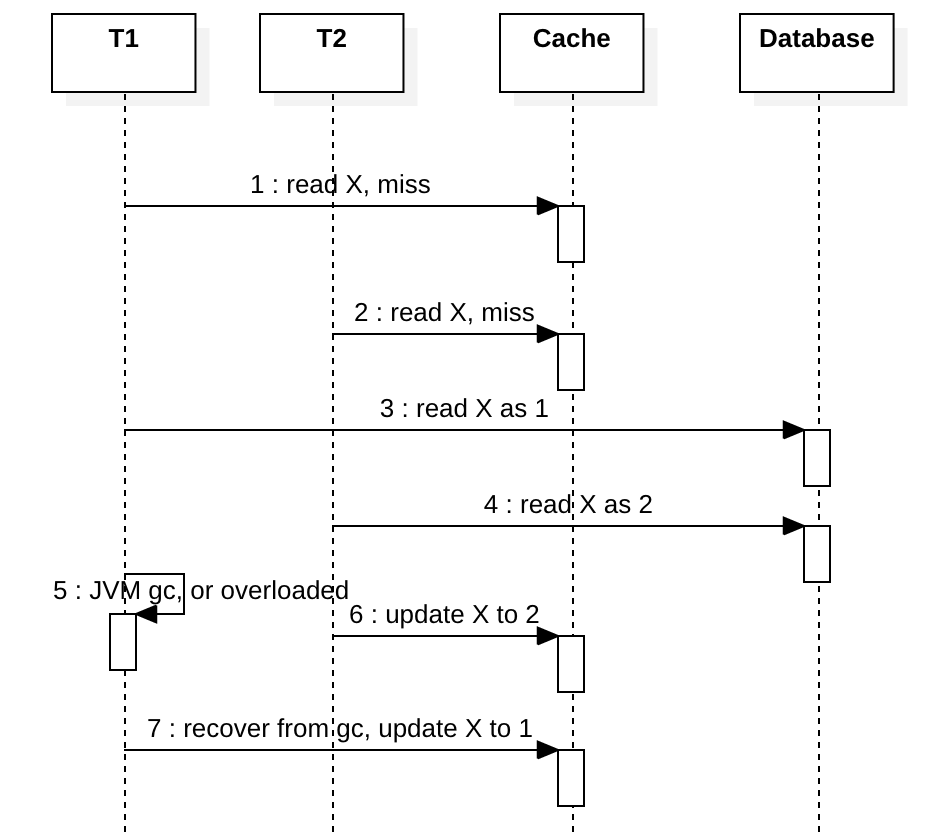
Using a distributed lock can solve this but it’s too expensive. A simple solution is to prevent T1 write stale data at step 7 by CAS. Most modern cache system supports CAS write (e.g. Redis Lua), we can use CAS write with a version to ensure writing order like this (implemented in Redis with Lua):
# Arguments
#KEYS[1]: the key
#ARGV[1]: old version
#ARGV[2]: new version
#ARGV[3]: new value
#ARGV[4]: TTL in seconds
# You can test in redis-cli:
eval "local v = redis.call('GET', KEYS[1]); if (v) then local version, value = v:match(\"([^:]+):([^:]+)\"); if (version ~= ARGV[1]) then return 1; end end redis.call('SET', KEYS[1], ARGV[2] .. ':' .. ARGV[3], 'EX', tonumber(ARGV[4])); return 0;" 1 key1 0 1 value1 1000
With CAS, at step 7 T1 will fail and T1 is able to query cache again to get the latest X.
A very special case is that if T1 pauses very long, long enough that the value of X written at step 6 expires, in that case T1 is still able to write the stale data to cache, but this is extremely rare to happen because T1 has to pause very long, maybe 15 minutes which is unlikely to happen. So, this is just a possibility in theory. If you want to solve this, consider using a timestamp when writing to cache, and the cache system can reject the write if it’s too old. e.g, the expiration is set to 5 minutes, if the write with a timestamp older than 5 minutes, reject and report an error so the client can be aware of this and retry. However, any timestamp-based solution is vulnerable to clock drift and you must have the correct NTP setup.
Concurrency in Write-through
Suppose we don’t use a distributed lock to coordinate T1 and T2, both T1 and T2 try to update X.
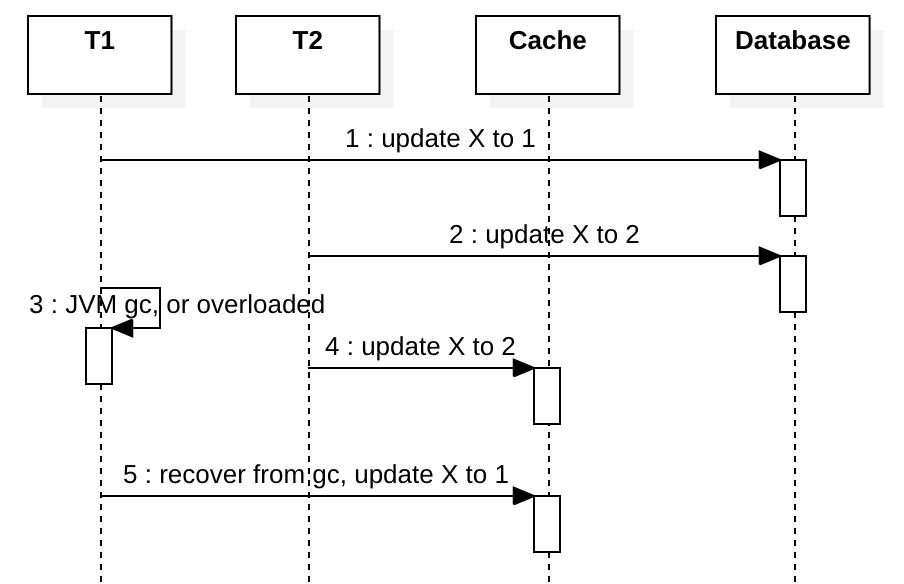
After step 2, ideally, T1 should update the cache to 1, but if something like a JVM full GC happens in T1 meanwhile T2 updates cache and write X to the latest value 2, then T1 will write its stale value 1 to X in the cache. This is similar to the concurrency problem mentioned before, but this happens more likely, it doesn’t require two concurrent cache misses which is rare.
To solve this kind of problem without a distributed lock, you can use the write-invalidate pattern with the read-through pattern. At step 4/5, we just invalidate the cache key and the next read should recreate the cached data. This way, T1/T2 both will see X as 2 in the next read, if another T3 reads X between step 4 and 5, it sees a cache miss and will try to load the cache from the database, and it sees X as 2. Now we achieve linearizability consistency level. The drawback is obvious, in a write-then-read scenario, you will see a low hit ratio.
You can also use a CAS write with version check to ensure order, as we have demonstrated that in the last section. Each time you update the database you retrieve the version back (you can make it by Oracle sequence, simulating sequence in MySQL, distributed incremental key, lock the row to retrieve result), then only update the cache if the version of the incoming request is higher than the version in the cache to prevent step 5 to happen. Unless T1 pauses for a long time and X expires, which is rare, it should work in most cases. This solution is a little complicated and uses it only when you really need it.
Concurrency in Write-Invalidate
To solve the problem in write-through, we can use the write-invalidate pattern. If we change the “update X to …” to “invalidate cache” in the sequence diagram of write-through, it looks like this:
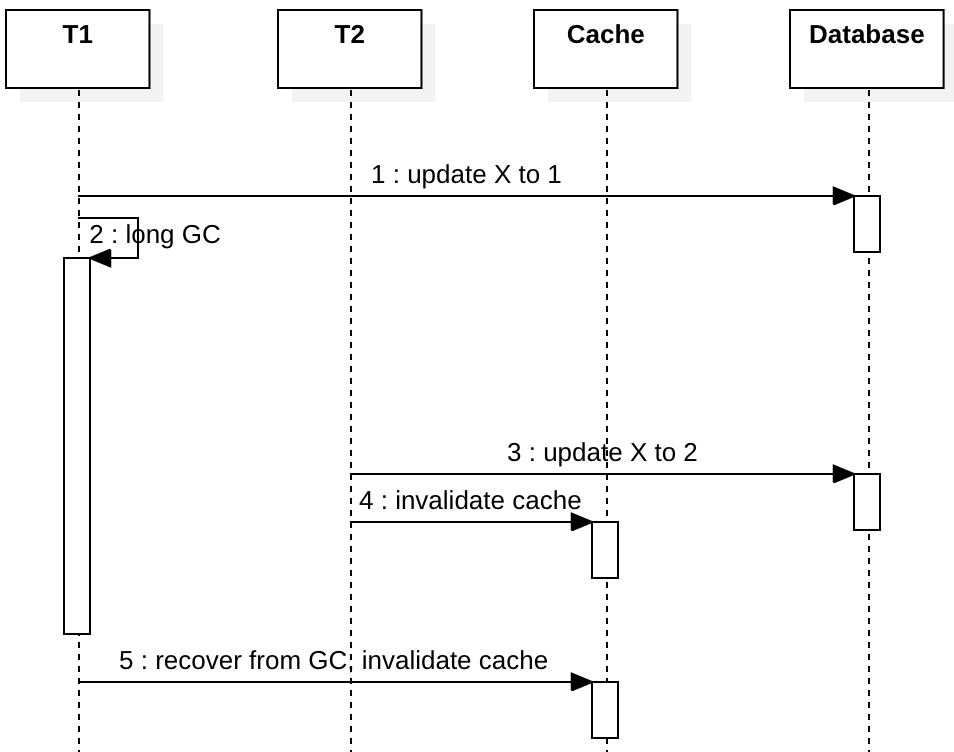
Then any subsequent reads will see a cache miss and re-populate the cache with the latest value. However, this only solves some of the data race scenarios between two write clients, it does not solve data race problems between a reading client and a writing client without a lock, it’s only best-effort eventual consistency, not sequential consistency. I will explain why in the next section. Before that, let’s how Facebook solves this problem with a pessimistic lock (lease).
Facebook published a paper in 2013 to explain how the Write-Invalidate pattern is used along with “lease”, which is actually a lock. From Scaling Memcache at Facebook 3.2.1.
Intuitively, a memcached instance gives a lease to a client to set data back into the cache when that client experiences a cache miss. The lease is a 64-bit token bound to the specific key the client originally requested. The client provides the lease token when setting the value in the cache. With the lease token, memcached can verify and determine whether the data should be stored and thus arbitrate concurrent writes. Verification can fail if memcached has invalidated the lease token due to receiving a delete request for that item. Leases prevent stale sets in a manner similar to how load-link/storeconditional operates [20].
Suppose T1 and T2 try to update the cache, only one client can update the database and the cache. e.g.,
T1 gets the lease
T2 fails to get the lease, wait
T1 updates and commits database
T1 returns the lease
T2 kicks in
The paper does not explain how to return the lease in case of error, but most likely it’s always sequential consistency even the leaseholder fails to return a lease. But obviously, the pessimistic lock will increase latency as the lock has a long lifespan until the database transaction is commited. If there are a lot of concurrent writes with a slow database, they will wait.
CAS with versioning without pessimistic locking is a better solution than this if throughput matters. Now let’s see why it’s difficult to achieve Sequential Consistency without a lock, when two clients read and write concurently with write-invalidate and read-through.
Concurrency with Write-Invalidate and Read-through
In the last section, we talked about how write-invalidate solves problems caused by write-through. But write-invalidate also has problems when it is used with read-through, which is a very common pattern used in many systems. Suppose we don’t use a distributed lock to coordinate T1 and T2, both T1 tries to read X and T2 tries to update X.
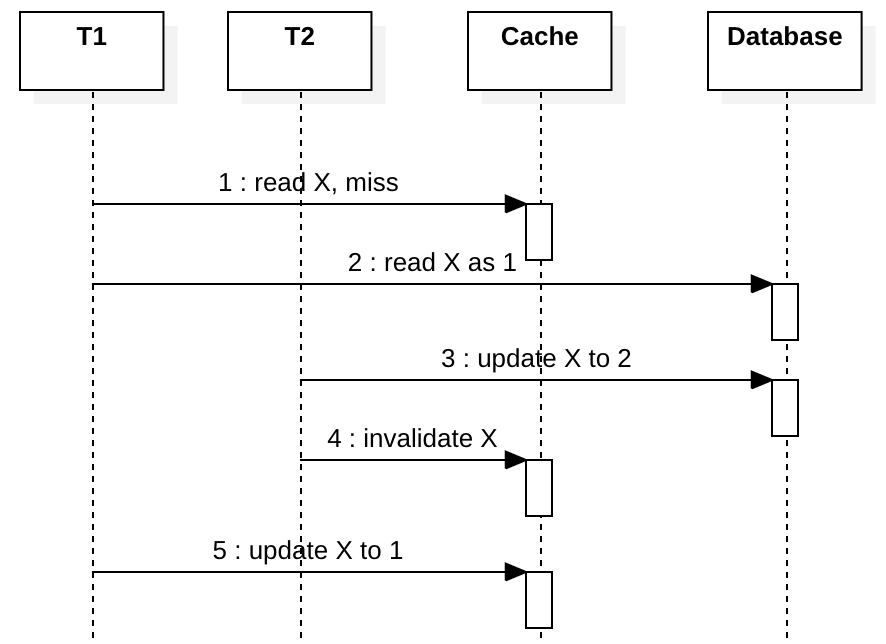
If T1 is overloaded and it is slow for some reason, step 5 could be deferred and write a stale value to cache.
The CAS write solution does not work with write-invalidate pattern, because once the cached key is deleted at step 4 you have nothing to compare with CAS.
Some people use something like a write-deferred-invalidate solution, that is, schedule the invalidation 500ms later asynchronously and return immediately after step 3. The idea is we hope we can predict how lag T1 is and make the invalidation after step 5.
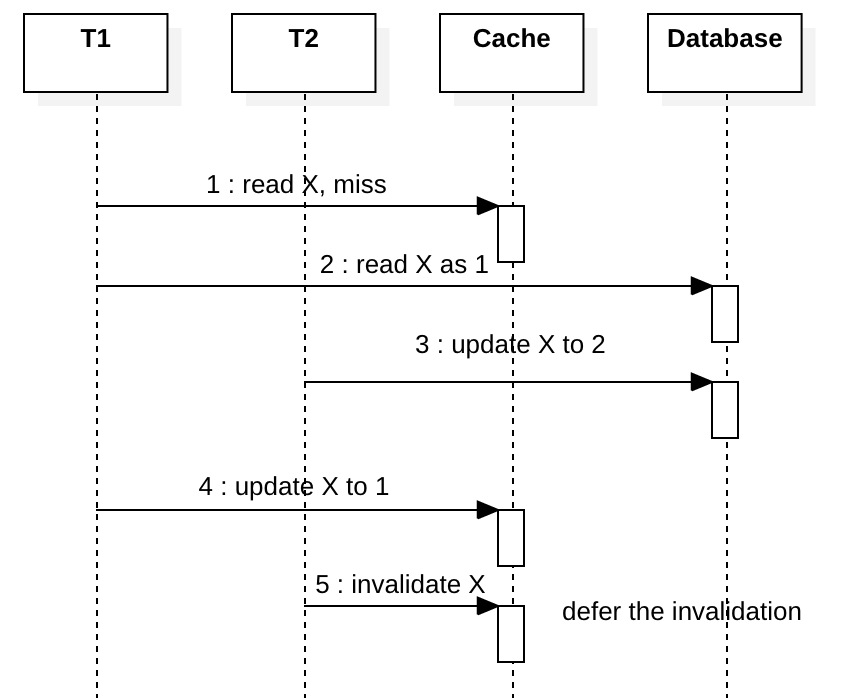
This solution also helps to hide database master/slave latency when you have a cluster of read-only slave databases. If T1 updates the master database, T2 reads from a slave database instance, T2 will not see the latest change made by T1 due to the replication latency, so T2 could populate stale cache, luckily the stale cache will be removed by T1 after 500 ms.
But this solution also has many drawbacks. First, in the case of updating an existing value in the cache, the new value always is removed with 500ms latency, that hurts the cache hit ratio. Moreover, this solution depends on the correct settings of the delay, which is often impossible to predict because it varies with loads, hardware change, etc. I don’t recommend write-deferred-invalidate, since predicting latency is just a gambling.
So, CAS is probably the only way to solve this kind of problem.
Other solutions
Double Deletion
This pattern is a write-through variant, originates from some engineers who want to invalidate the cache first, then write to the database. It’s a 3-step solution: 1) invalidate the cache. 2) write database 3) schedule a deferred cache invalidation. I don’t understand why they want to invalidate the cache before writing to the database, this only causes more inconsistency. And the 3-step solution is very expensive. Actually, this is very similar to the write-deferred-invalidate solution we just talked about in the last section, and I would not recommend this.
MySQL binlog to Cache
This is a solution of Alibaba engineers. They have a listener to receive MySQL binlog and populate cached data in Redis or other sorts of the cache. This way you don’t need to write cache in your application code anymore, the cache is populated automatically by the listener. And you have slave database instance lag, so you don’t need deferred cache invalidation. This solution satisfies the Sequential Consistency Model. Sounds cool, but this solution cannot handle cache in fine-grain, if you only want to cache 1% of your data (you have 100 tables and only one table need to be cached), you still have to process 100% of the binlog and drop 99% of the log entries. And you probably see higher latency since you have to handle asynchronous replication and parse binlog. If you have multiple databases or even multiple data centers, you must already have database replication, in that case, this solution is probably the easiest way to implement Sequential Consistency. Note, when using binlog to replicate database and cache, you must always process database then cache, if you fail to write to the database, you should stop writing to the cache, if you keep writing to the volatile cache, after cache expires, your application could see phantom data disapear and you can only get Eventual Consistency. If you can update the cache in each data center from both binlog and local applications, that’s very complicated and beyond the scope of this article. For more details on that, read the chapter “Across Regions: Consistency” from the facebook’s paper to see how a “remote marker” can be used to mitigate the inconsistency.
Cache Failures
Read-through doesn’t introduce any problem if the updates to cache fail, except increasing database load. If the update to cache fails with write-through or write-invalidate, you will not be able to see the latest value until another successful write or cache expires. When you combine all these cache patterns to work together, things become complicated.
Conclusions
It’s often impossible to implement a linearizability consistency model with distributed cache and database systems considering all kinds of errors and failures. Every cache pattern has its limitation and in some cases you cannot get sequential consistency, or sometimes you get unexpected latency between cache and database. With all the solutions I showed in this article, there are always corner cases that you might encounter with high concurrency. So, there is no silver bullet for this, know the limitation and define your consistency requirement before you choose a solution. If you want linearizability consistency with fault-tolerance, you’d better not use cache at all.