消息可靠性和顺序(中文)
概述
在分布式系统中,消息可靠性是数据一致性的基础,通常需要一次或至少一次传递消息。实际上,严格来讲,没有人能够以完全一次(exactly once)的保证来实现消息传递系统,这是不可能实现的。实际上,我们让用户方至少一次处理幂等和排除重复数据,以模拟exactly once语义。实际上,即使是at-least once也不容易实现,我们将在本文中讨论原因。我们还将讨论消息传递一致性问题中最困难的部分: 顺序(ordering)。
可靠性
一个可靠的消息传递系统要求消息将始终及时传递。因此,最重要的是最终至少要传递一次消息而不会丢失。换句话说,所有三个参与者都需要确保交付期间的持久性(通常需要权衡吞吐量和延迟),整个端到端系统必须能够承受崩溃。持久性并不是那么容易确保,因为生产者,经纪人和消费者中都有缓冲区,崩溃可能会丢失一些消息。在本节中,我们将展示如何确保三个参与者(生产者,经纪人和消费者)的持久性。
Producer 可靠性
Producer Buffer
大多数MQ框架在生产者端都具有in-memory buffer或TCP Socket buffer,以提高批处理或管道性能。但是缓冲区是易失的,如果连接断开或进程崩溃,缓冲区中的消息可能会丢失。
RabbitMQ API没有本地内存缓冲区,它仅使用套接字缓冲区。与RabbitMQ代理的TCP连接断开时,生产者的套接字缓冲区将丢失,因此您未发送的消息将会丢失。尽管RabbitMQ具有连接自动恢复功能,但它并不能帮助保持一致性,自动恢复还是会丢弃TCP缓冲区中的所有数据。另外当生产者崩溃或重新启动时,即使您拥有完美的网络,套接字缓冲区中的所有消息也都消失了。
Kafka生产者API是异步的,它具有一个内存缓冲区。 Kafka还具有一个套接字缓冲区,可以通过“socket.send.buffer.bytes”(SO_SNDBUF)对其进行调整。如果发生网络故障,套接字缓冲区中的消息可能会丢失;如果生产者崩溃,则两个缓冲区中的所有消息都将消失。
由于缓冲区的非持久性(volatile),仅当接收到ACK时,消息才被视为已发送。所以RabbitMQ和Kafka都提供了ACK应答机制。
使用Kafka时,您可能需要限制缓冲区大小(“buffer.memory”)或缩短等待时间(“linger.ms”)。如果生成事件的速度太快,或者在一个JVM进程中有太多繁忙的生产者,则生产者可能会耗尽内存并崩溃。当然,如果您想要最佳的可靠性,则需要刷新缓冲区并针对每条消息进行确认,这肯定会降低您的应用程序的速度。
Producer-Broker ACK in RabbitMQ
RabbitMQ发送成功的ACK叫做Confirm,拒绝的NACK叫做Return。
Once a channel is in confirm mode, both the broker and the client count messages (counting starts at 1 on the first confirm.select). The broker then confirms messages as it handles them by sending a basic.ack on the same channel. The delivery-tag field contains the sequence number of the confirmed message
用Java编程时,看起来像这样
channel.confirmSelect(); // enable confirm
channel.basicPublish(exchange, queue, properties, body);
// option 1, blocking, wait for ACK(Confirm) and NACK(Return)
channel.waitForConfirmsOrDie(5000);
// option 2, non-blocking
channel.addConfirmListener((sequenceNumber, multiple) -> {
// code when message is confirmed (ACK)
}, (sequenceNumber, multiple) -> {
// code when message is returned (NACK)
});
在Broker端,对于持久队列仅在将消息持久保存到磁盘后才返回ACK消息。如果您有mirror queue,则意味着所有mirror queue都已经持久化此消息。如果您有quorum queue,则意味着超过一半的队列副本已经持久化了此消息。对于非持久队列,只要enqueue到内存就算ACK。
NACK是在一个mandatory消息无法路由后者队列满了到时候返回。我强烈建议设置“mandatory=true”。如果没有此选项,则如果一条消息不可路由,它将被静默丢弃。启用它会导致“basic.return”返回给生产者。
AMQP协议提供“transaction”以确保可靠地发布消息,但是我强烈建议您不要使用它,因为它将使吞吐量降低250倍。
Producer-Broker ACK in Kafka
Kafka使用术语“回调”表示ACK。 在这里我仅向您展示回调的API。
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
在Kafka Java客户端中,send()接受一个回调并返回一个Future,当send()返回时并不表示它已发送,这意味着它现在在缓冲区中。 然后Sender.run()循环以通过NetworkClient.poll()检查响应。 如果完成任何响应(消息已离开内存缓冲区或套接字缓冲区,已进行ACK轮询),它将在Sender线程中执行您的回调。 至此,您的消息才算是已“发送”。
您还可以在Kafka客户端中使用flush(),它等待所有topic的内存缓冲区和套接字缓冲区消费完,并等待所有批处理都得到broker的ACK,然后执行所有回调,最后同步返回。 flush()和callback共享相同的代码路径,但是flush()是同步的,并且会影响所有主题,回调是针对每条消息的,并且是异步的,因此请尽可能使用callback。
消息和数据库事务
当我们需要发送消息并提交一些数据库更改时,存在一个难题,我们应该在事务中还是在事务之后发送消息?
下图显示了第一个选项,它在事务内发送消息。 该消息是在事务提交之前发送的。 问题是,如果在步骤5事务回滚,则消息已发送,并且无法撤回该消息。 消费者将收到引用一些幻象数据的幻象消息。
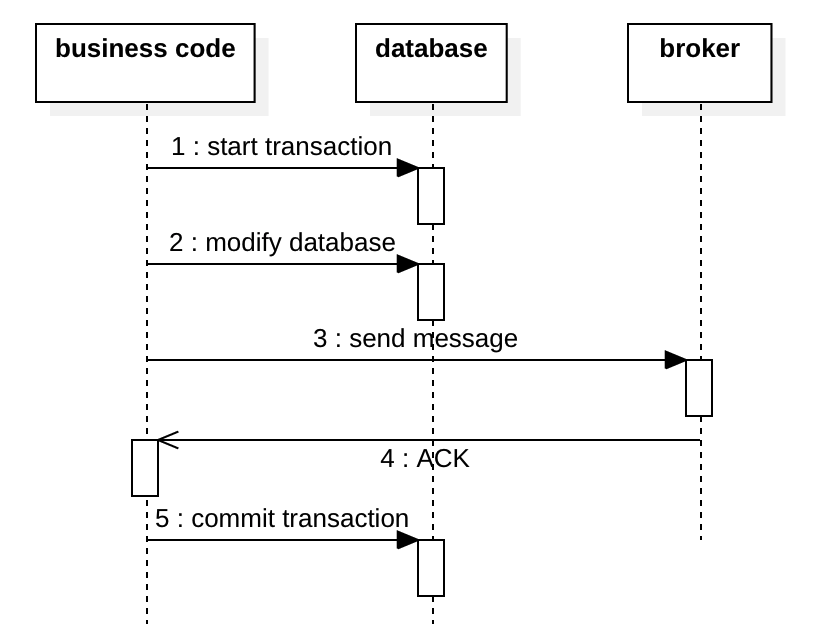
下图显示了第二个选项:在交易之后发送消息。 这也存在问题,如果步骤4的发送失败,则下游系统将永远不会收到该消息。
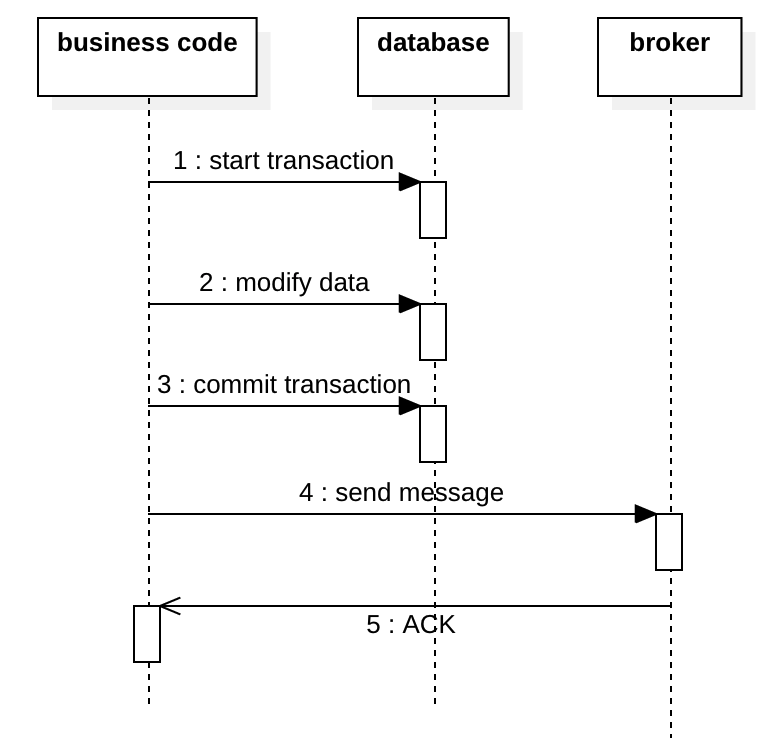
为了解决这个问题,ebay 架构师 Dan Pritchett 在 2008 年发表的一篇论文[1]中描述了 outbox模式。 在这种模式下,我们有一个outbox表来保存要发送的消息。 该消息与数据库事务一起提交,这确保了该消息与业务数据原子地持久化。 然后,异步作业将扫描待处理的消息,并将其发布到代理,如果成功,则将消息更新为“已发送”,并在以后进行归档。
Outbox 模式
以下是outbox模式的过程。
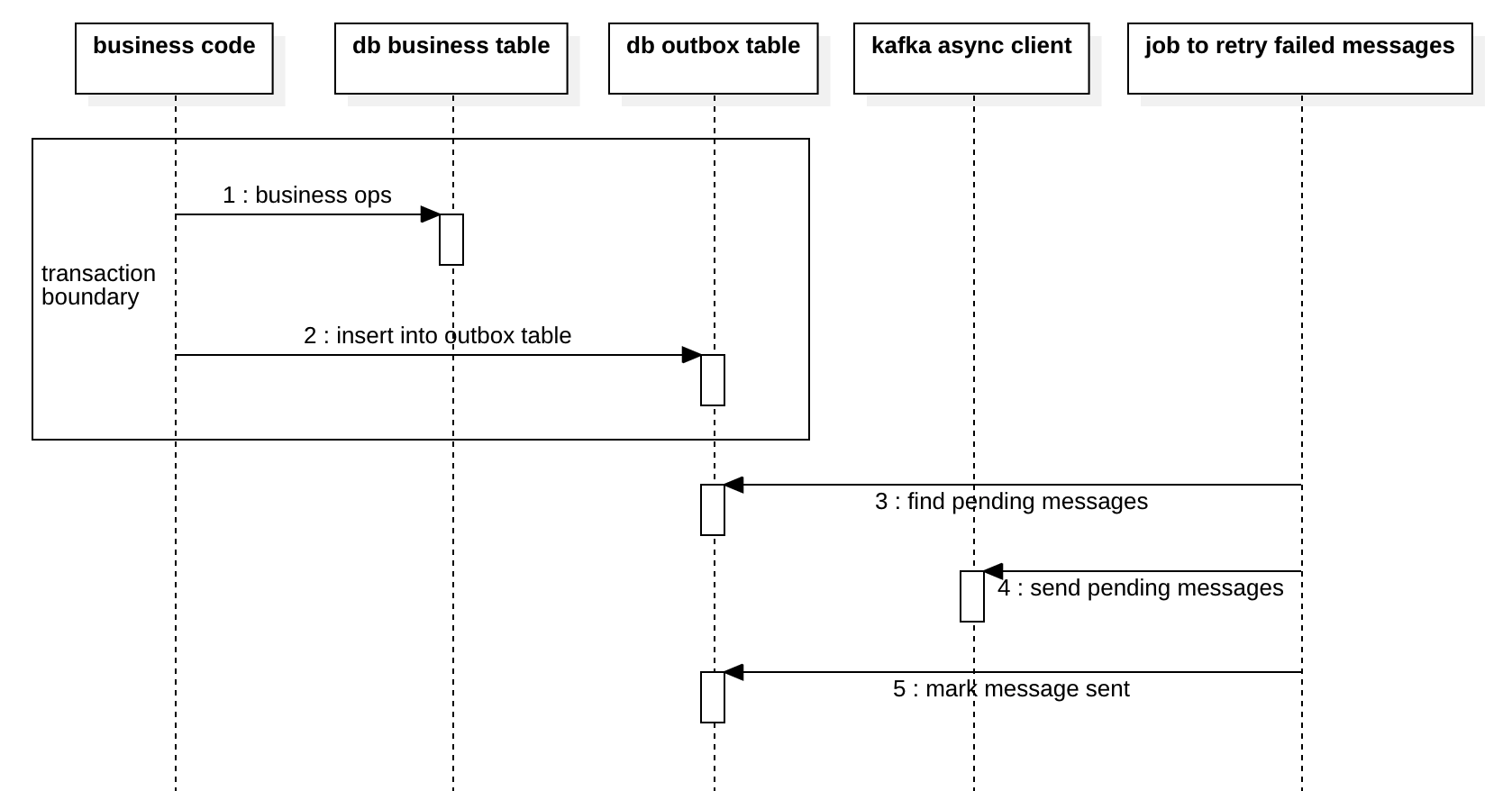
在实现outbox模式时,开发人员常常会误解在第4步中的“发送”,并且在某些情况下仍然会丢失消息。 主要原因是生产者和代理通常使用本地缓冲区,我们将在接下来的两节中讨论这一点:生产者缓冲区和代理缓冲区。
由于job具有计划的时间间隔,因此将按时间间隔批量发送消息,这可能会导致高延迟。 因此,我们还可以进行一些优化以降低延迟,如下图所示,我们将立即在步骤3触发job。但是,此优化不适用于严格的总排序,我们将在本文后面进行讨论。
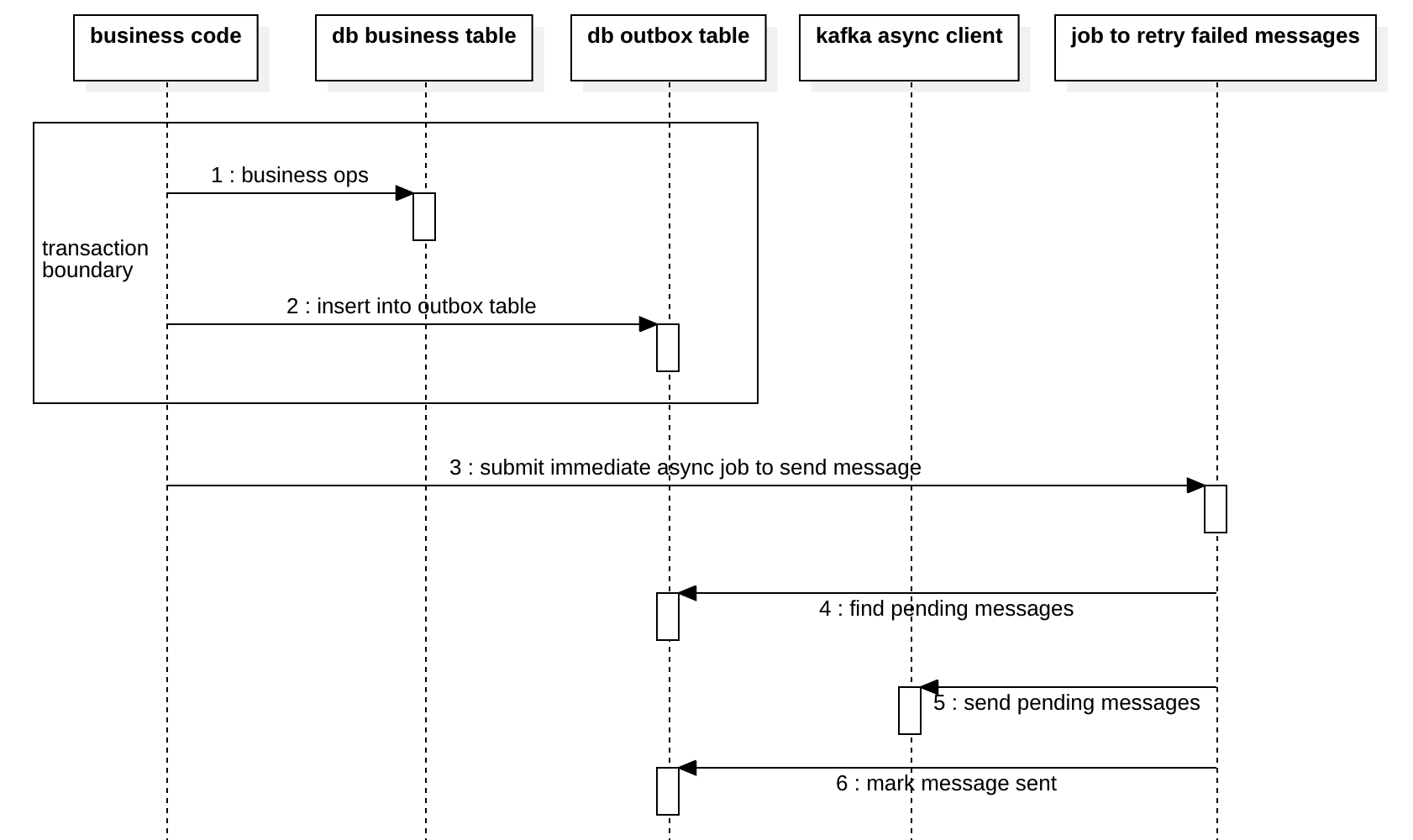
注意,在实现outbox模式时,困难之一是使多个服务实例协调运行job,避免竞争,以查找pending或failed的消息并发布它们。 这通常是在Zookeeper或etcd的帮助下以选举方式实现的。 因此,这种方式使用一个leader完成所有工作,这肯定有点慢。 也许您可以有多个outbox表,因此每个outbox都有一个leader,以避免争用。 但这将破坏消息的排序,我们将在后面讨论。
另一个问题是,当您在上图中的第3步进行了低延迟优化时,您需要避免对同一条消息同时发生第3步和第4步。 为避免这种情况,使用某种外部锁定过于昂贵,我们可以使job仅扫描较旧的待处理消息,以避免发送重复的消息。
很多人倾向于在表上加一个列来表示消息是否已经发送,这样可以避免一张新表所带来的额外的存储空间和IO开销。但是这种优化的适用场景非常有限。首先,他只适用于非常简单的场景,在涉及多表复杂的事务中你很难决定这个列加在哪个表上更合适,其次,你的数据必须是immutable的(一旦写入不再更改,比如金融应用,账本)否则的话,当你发送消息的时候,数据可能已经变过很多次了,你无法重建出来原始的消息结构.
最后,你要注意poison message的处理,如果一个消息在scan出来之后多次处理都失败,那么你需要把它报告给运维,不要让它阻碍其他正常消息的处理。
Broker 2PC Pattern
由于我们上面提到的三个难点,RocketMQ 提供了一个非常不同的解决方案。开始你的事务之前,你先向broker发送一个“half-message”或“prepare-message”,在您完成transaction并在下图中的第 5 步确认该消息之前,该消息不会交付给消费者。
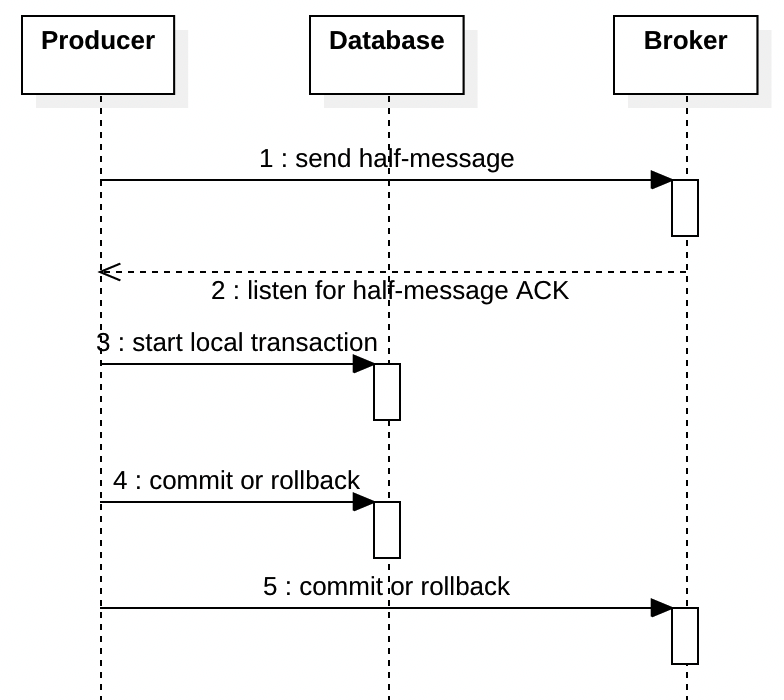
如果事务在第 4 步回滚,则生产者应在第 5 步通知broker,然后代理将取消该消息,消费者将永远不会看到它。如果生产者在第 5 步崩溃,则代理将尝试查询生产者以检查是否应提交或回滚事务来确保事物一致性。所以producer需要写一个查询接口。
与outbox模式相比,这种模式大大简化了您的代码,而且速度也更快,因为向代理发送消息通常比将记录插入outbox表要快。但它有一个很大的缺点。当broker崩溃时,由于half-message无法被broker确认,即使数据库仍然健康,事务也会失败。而使用outbox模式的好处是,事务仍然可以提交,事务将在稍后broker恢复后继续提交和处理。
大多数情况下我还是倾向于使用Outbox模式。因为我很难接受broker crash导致我的数据库事务无法提交。
Broker 可靠性
Broker Buffer
即使我们在broker和producer之间具有ACK,在broker端仍然有可能丢失消息。 这取决于broker如何答复ACK。 如果消息尚未持久保存到磁盘时,broker就回复ACK,则此时节点崩溃将导致broker缓冲区中的消息丢失。
RabbitMQ仅在消息“持久到磁盘”后才返回ACK,因此,当生产者收到ACK时,该消息已保留。 如果您使用的是mirror queue,则表示消息已在所有mirror queue中持久化。 如果使用quorum queue,则意味着超过一半的副本已持久化该消息。
Kafka会在收到消息的时候返回ACK,而这时消息还没保留到磁盘上。 因此,使用Kafka的时候一般您必须设置replication以避免消息丢失。
这又是性能和可靠性之间的折衷。
Durability with Cache
操作系统页面缓存可以由fsync()控制,Broker定期调用fsync()或在发送ACK(RabbitMQ confirm)时调用。诸如Apache Qpid之类的某些代理在fopen()上具有O_DIRECT选项以禁用页面缓存。但这仅适用于在您具有RAID缓存的情况下,否则,尽管您具有数据安全性,但系统将非常慢。
RAID高速缓存不能由操作系统控制。如果您没有BBU,则可能需要将RAID缓存策略设置为write-throughs,虽然安全一些但这很慢。为了提高写入性能,您最好拥有BBU,并将缓存策略设置为write-backs(write-behind)。
磁盘内部缓存是磁盘内部的一个非常小的缓存,大约32MB至128MB。如果您将RAID卡与BBU一起使用,则可以禁用它。请注意,某些新磁盘具有非易失性磁盘缓存,在这种情况下,您仍然可以启用它,这样您将具有两层非易失性缓存。
配置了安全的缓存策略后,您的服务器仍然有可能因某些硬件故障而崩溃。因此,大多数代理都具有复制支持。 RabbitMQ具有mirror queue和quorum queue来实现复制,Kafka通过分区来实现复制。因此,接下来,让我们谈谈复制的持久性。
Durability with Replication
RabbitMQ的每一个mirror queue 由一个master和多个mirror组成。 给定队列的所有操作都首先应用于队列的master节点,然后传播到mirrors。 这涉及排队发布,将消息传递给使用者等。在所有节点都保留消息之后,leader才会返回生产者ACK(confirm),这是一个非常有力的保证。
默认情况下,如果队列的主节点发生故障,则最老的mirror queue将被提升为新的主节点。 在某些情况下,此mirror queue可能是unsynchronised。 如果您始终使用ACK(publisher confirm)和mirror queue,则仅当消息在所有节点上持久存储后我们才接收ACK,因此我们不必担心节点之间的数据同步。 对于没有发布者确认的mirror queue,您可能会遇到unsynchronized的队列。 在这种情况下,如果要保持一致性,则需要将ha-promote-on-failure设置为when-synced,然后尝试手动恢复发生故障的节点。 如果需要可用性,可以将其设置为always,然后尝试重新发送可能丢失的消息。
RabbitMQ 3.8之后还提供了更加简单安全的Quorum Queues .
Kafka的分区复制类似于镜像队列,但是ACK模式更加灵活,消息经过ACK’ed并以3种模式持久化:
acks = 0:生产者根本不会等待服务器的任何确认。 该记录将立即添加到套接字缓冲区中并视为已发送。
acks = 1:leader会将记录写入其本地日志,但不等待所有follower完全确认的情况下就做出响应。 在这种情况下,如果leader在确认记录后但在follower复制记录之前crash,则消息将丢失。
acks = all:这意味着leader将等待所有ISR确认记录。 这保证了只要至少一个ISR仍处于活动状态,记录就不会丢失。 这是最有力的保证。
因此,为了获得可靠的消息传递,您可能需要acks = all,以防服务器崩溃并且无法及时恢复。
设置acks = all确实很慢,如果您想获得更好的性能,可以设置acks = 1,然后禁用“unclean election”。 然后,在leader崩溃的情况下,如果一个ISR都没有,则在leader恢复之前该分区将不可用。 (请参阅unclean.leader.election.enable)。 这是可用性和一致性之间的权衡。 实际上,我想选择可用性的同时,尽量满足一致性。 也就是说,我们可以设置acks = 1并启用“unclean election”。 如果我们有完善的监控(例如Prometheus中的UncleanLeaderElectionsPerSec),我们可以检测到unclean election,那么我们可以将发件箱中最近的message的状态还原为“pending”,然后再次发送以避免消息丢失。 但这将破坏每个分区中的全局顺序保证。 我们将在本文后面讨论顺序。
Consumer 可靠性
在消费者方面,通常我们需要原子处理数据库事务的消息。 换句话说,如果消息ACK失败,则不要提交事务,如果消息是ACK,则必须提交事务。
如果我们在提交事务之前对消息进行了确认,万一后面的数据库上的业务操作失败,这个消息相当于没有触发业务操作。这显然是不可接受的。
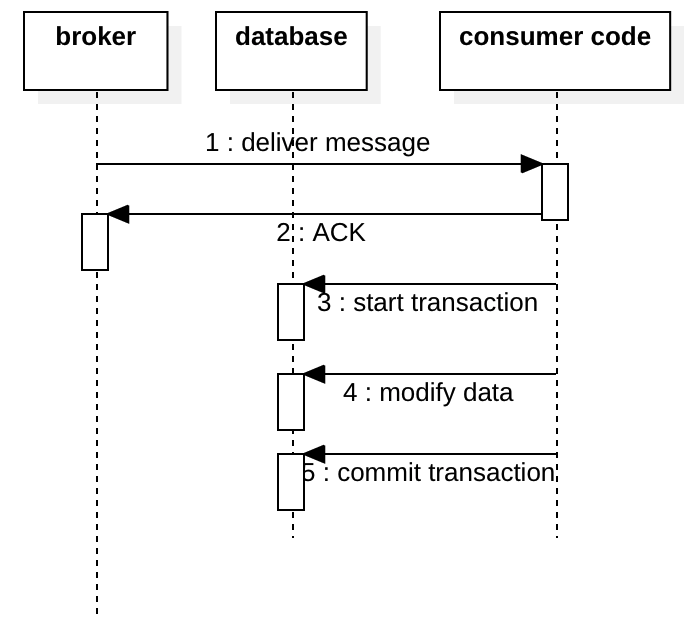
如果我们在事务中对消息进行了确认,我们会遇到和事务前确实一样的问题。比如我们在下图的第5步中未能提交事务,则由于已对消息进行了ACK,因此我们将再也没有机会再次使用它,数据库中的数据将永远不会 被更新。
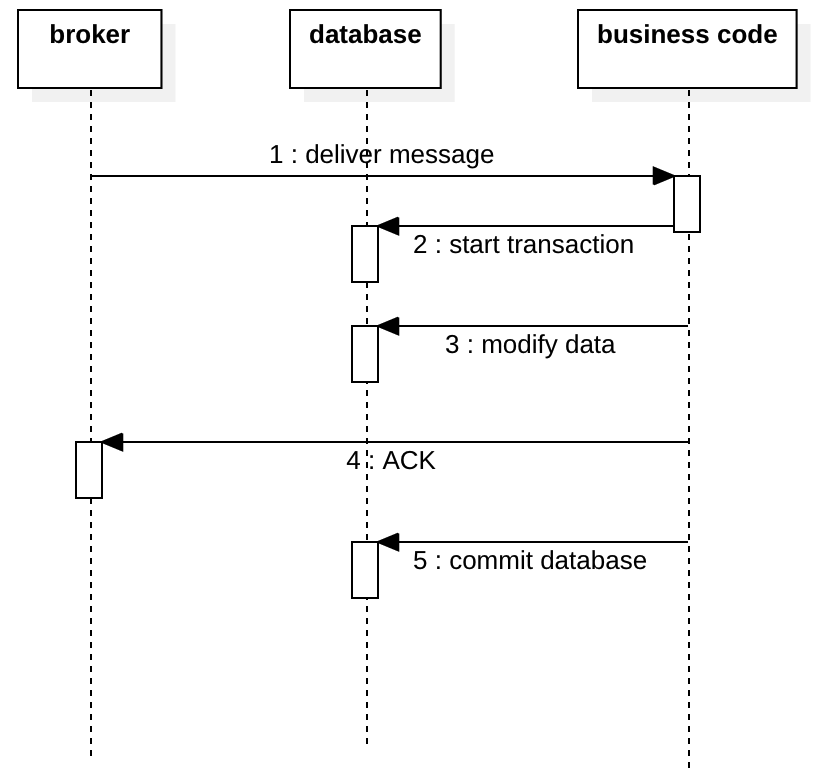
处理此问题的更好方法是在事务处理后对消息进行确认。 如果事务已提交但消息未确认,我们稍后将再次收到这个消息。 如果您的消息处理是幂等的,或者您具有分辨重复数据的能力,你相当于具备了exactly-once的能力。请参见下图:
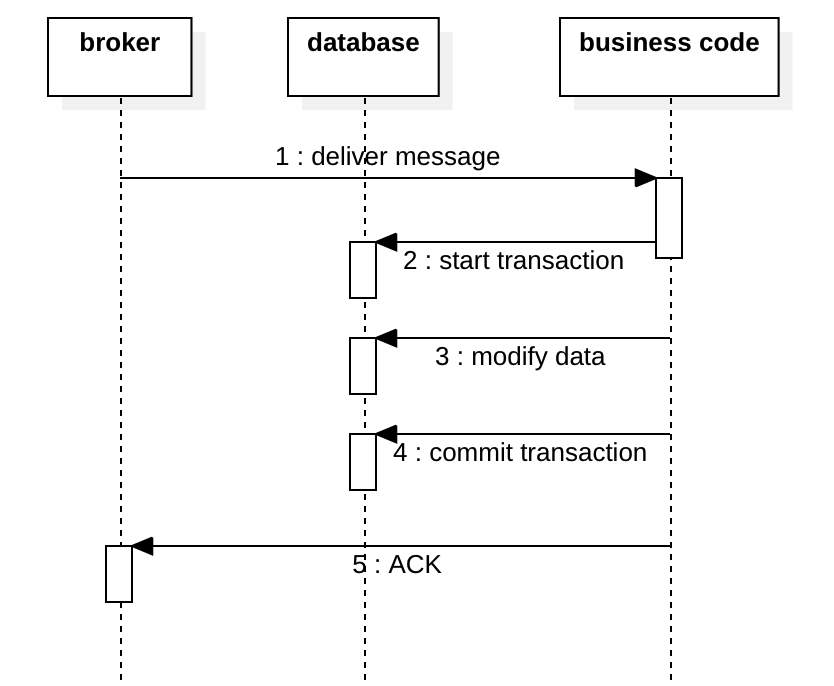
但是,消费者ACK其实有点小复杂,许多人不正确地理解它。
Consumer ACK mode
在AMQP中,有一个Auto ACK模式,您必须禁用它并手动确认该消息。 Spring也具有“auto ACK”功能,但与AMQP中的“Auto ACK”概念完全不同。 有关更多详细信息,请参阅AcknowledgeMode.
在Kafka中,您可以同步或异步ACK。
void commitSync();
void commitAsync();
void commitAsync(OffsetCommitCallback callback);
始终建议使用异步,因为消费者ACK并不是很关键。 如果消费者ACK没发出去,您也就是再次消费一次这个消息。 如果您可以分辨重复数据或者您的处理是幂等的,那就没问题。
有一种特殊情况是当您必须使用一些消息,对其进行处理,然后将一些结果发布回Kafka时,可以使用Kafka事务。 有关更多详细信息,请参阅Kafka交易。
Consumer Buffer
对于RabbitMQ,prefetch其实就是consumer的缓冲区。 AMQP具有内置的flow control,如果正在运行的消息达到prefetch大小,则consumer将停止消费消息。您不需要为此编写任何代码,AMQP很酷吧?
对于Kafka,因为它是按批处理模式设计的,所以没有内置的流控制,因此我们需要限制使用者缓冲区的大小并在缓冲区已满时停止拉取,否则,应用程序将遇到OOM并崩溃,然后您的consumer(应用程序)将被逐出consumer group,并在以后rejoin。有时rejoin和rebalance过程可能需要5分钟,这是一个严重的问题。更糟糕的是,如果长时间没有消息到达,也可能导致消费者被赶出consumer group。没有flow control的情况太糟糕了!
要使用不提供内置flow control的Kafka构建可靠的系统,您需要自己编写某种流控制。例如。当缓冲区快满时,您需要从使用者端动态增加提取间隔,增加“ max.poll.interval.ms”或减少“ max.poll.records”。如果您觉得实作太难了,干脆就使用较小的使用者缓冲区算了。
Poison Message
有时,队列中可能存在格式不合法的消息,如果使用者无法正常解析消息,则它只会引发异常并re-queue重新排队该消息。 然后,我们将一次又一次地传递,解析和重新排队该消息,进入无限循环。 要构建可靠的消息传递系统,必须确保您有某种方法可以检测这种有毒消息并将其丢弃或将其发布到其他队列中。
消息顺序
许多人谈论消息排序,但通常不同的人对消息顺序有不同的理解, 大家一起讨论消息顺序的时候经常是鸡同鸭讲。 在这里,我们明确定义了消息顺序的两个不同概念来避免混淆:队列投递顺序(Broker Delivery Order)和业务事件顺序(Business Event Order)。
队列投递顺序 (Broker Delivery Order)
队列投递顺序意味着,如果消息A在B之前到达Broker,则A也应该在B之前被消费。在Kafka中,单个分区中的消息按投递顺序消费的,满足Broker Delivery Order。 RabbitMQ中,如果您在使用方禁用了prefetch,只有一个consumer,并且每次仅处理一条消息,那么您基本确保了队列投递顺序。 确保队列投递顺序的代价是执行效率很低。出乎很多人的意料,其实在大多数情况下,队列投递顺序是没有用的。 稍后我们将解释原因。
业务事件顺序 (Business Event Order)
业务事件顺序表示消息是按因果顺序生成和处理的。 例如,您的存款帐户从$0变为$1000,然后从$1000变为$500,下游消息消费者必须能够识别这两个事件的业务顺序。 如果下游首先收到事件$1000至$500,然后收到$0至$1000,则它必须能够识别出两条消息是乱序的,并在处理它们之前对其重新排序。
另一方面,如果将两个事务应用于两个帐户,并且这两个事务不在两个帐户之间操作,则可以说两个事务是独立的,之间没有因果关系,那么消费者可以按任何顺序处理这两个事件。 例如,事件A表示在帐户X上提款,事件B表示在帐户Y上存款,这两个事件无关紧要,没有因果关系,消费者可以按任何顺序对其进行处理。但是如果事务是从X转账到Y,再从Y转账到X,那么我们就要严格按照业务逻辑顺序重新排序和消费这两个消息。
另一方面,如果将两个事务应用于两个帐户,并且这两个事务不是在这两个帐户之间操作,则可以说两个事务之间没有因果关系,那么消费者可以按任何顺序处理这两个事件。比如X的账户从$0变为¥1000, Y的账户从$100变成$200, 这两个消息是没有任何因果关系的,消费端如何处理都可以。
还有一些情况我们并不需要完整的消息历史,比如一个记录超市访客数量的消息,如果我们先收到一个消息说现在累计了200访客,然后又收到一个消息说现在累计了100访客,我们可以直接丢弃100访客这个消息,因为这里业务上人数一定是单调递增的,我们不需要一个复杂的状态机和完整的历史消息,也不需要重新排序,我们只要丢弃一些消息即可,这种情况我们仍然满足业务事件顺序。
因此,业务事件顺序是指辨别出因果相关的消息,无论broker投递顺序如何,我们都能按预期的业务顺序对其进行重新排序,丢弃和处理。 业务事件顺序才是您真正需要的“顺序”。
我们需要什么样的消息顺序?
假设我们有两个生产者P1和P2,以及一个消费者C。P1发送m1,然后P2发送m2,并且m1和m2之间存在因果关系,换句话说,必须在m2之前处理m1。
看下图,消费者会先消费m1,然后再消费m2,一切很正常,对吗?
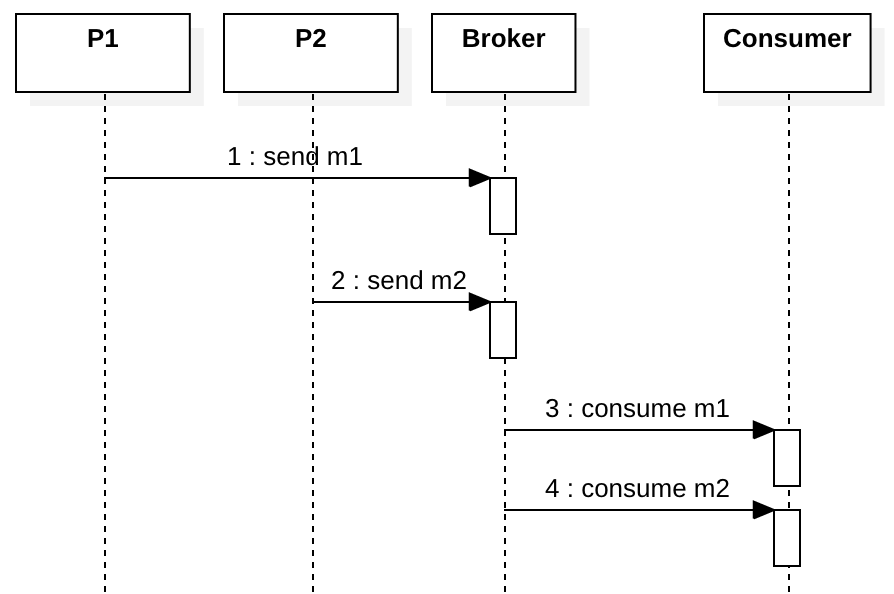
现在让我们考虑m1失败的情况。 如果稍后在第3步重新发送m1,尽管我们有完善的队列投递顺序,但消费者会使用错误的业务事件顺序来消费消息。
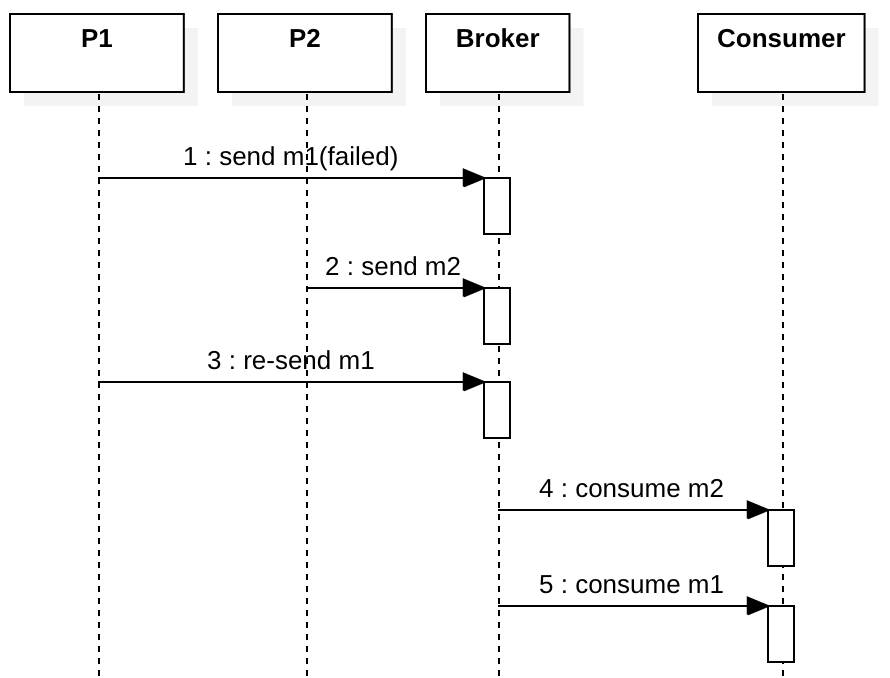
这是一个非常简单的示例,队列投递顺序是完全没有用的,它不仅没用,还会极大影响到你的系统吞吐[1]。您真正需要的是业务事件顺序,事件很难按业务事件顺序到达broker。
如果您有多个consumer,他们还需要仔细按照业务事件顺序处理消息。 例如,下图显示了消费者C1收到m1,然后C2收到m2。 理想情况下,在C1处理了m1之后,C2应该收到m2。 如果没有锁,那么两个消费者会并行处理m1和m2,这就违反了业务事件顺序。
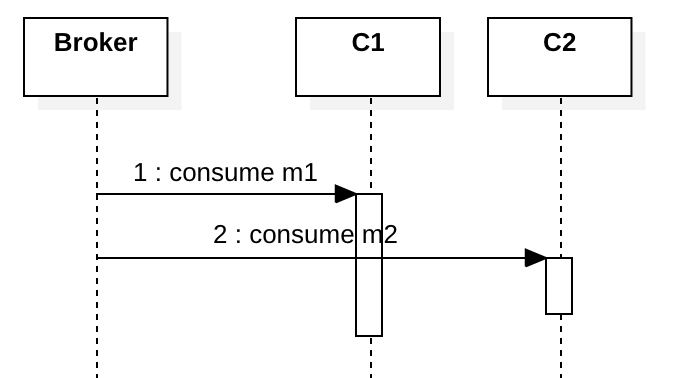
要按业务事件顺序处理消息,您实际上并不需要全局锁或只启动单个consumer,或者只选举一个consumer leader,这些解决方案提供了线性化级别的一致性(Linearizability Consistency),但是在大多数情况下它们太慢且不必要。 实际上,我们只关心因果级别的一致性(Causal Consistency), 只要能找出业务相关的消息,就可以按照事件顺序处理。 为此,我们可以在消费者端为那些因果相关的消息提供状态机,如果消息出现故障(过早),我们可以将其本地存储在“收件箱”中。 稍后,当延迟的消息到达时,我们将状态机触发到下一个状态,然后检查收件箱以查看是否存在下一条期望的消息,或者继续等待下一个消息。如果不需要完整的历史,有时候我们也可以通过版本号发现晚到的消息并丢弃它。
回顾一下,您不需要毫无意义的队列投递顺序,您真正需要的是业务事件顺序,并且可以在消费者端使用收件箱和状态机,或者丢弃一些无用消息,来提供Causal Consistency一致性消息排序。 您的代码永远不会依赖于队列投递顺序,这是没有意义的,不会帮你解决业务上的问题。
总结
- 消息可靠性并不像许多人预期的那么容易,您需要了解很多细节,包括缓冲区,缓存,复制,领导者选择和故障转移。
- Exactly-once 需要在at-least-once的基础上使用幂等或去重来实现。
- 队列投递顺序毫无意义,您的应用程序应该能够处理业务事件订单中的消息,即使broker无序地发送消息也是如此。
参考
- Dan Pritchett, Ebay “Base: An Acid Alternative” ACM QUEUE May/June 2008