Messaging Reliability and Ordering
- Overview
- Reliability
- Message Ordering
- Conclusion
- References
Overview
In a distributed system, message reliability is the basis of data consistency, it’s often required to deliver messages exactly-once or at-least-once. In fact, strictly speaking, nobody can implement a messaging system with exactly-once guarantee, it’s impossible to implement. In reality, we have the consumer side to handle idempotency and deduplication on top of at-least-once, to simulate the semantics of exactly-once. Actually, even at-least-once is not that easy to implement and we will discuss why in this article. And we will also discuss the most difficult part of the consistency problem of messaging - the ordering.
Reliability
A reliable messaging system requires that a message will always be delivered timely. So the bottom line is to deliver the messages at least once eventually, without losing. In another word, all three participants need to ensure durability (often trade-off throughput and latency) during delivery, the end-to-end systems as a whole must be able to survive crashes. Durability is not that easy to ensured because there’re buffers in the producer, broker, and consumer, a crash could lose some messages. In this section, we will show how to ensure durability in the three participants: the producer, the broker, and the consumer.
Producer Reliability
Producer Buffer
Most MQ framework has in-memory buffer or TCP socket buffer at the producer side to improve batch or pipeline performance. But the buffer is volatile, in case of a broken connection or process crash, the messages in the buffer could be lost.
RabbitMQ API does not have a local in-memory buffer, it uses the socket buffer solely. When the TCP connection to RabbitMQ broker is broken, producer socket buffer is gone and you lose messages. Although RabbitMQ has connection auto-recovery, it does not help with consistency and it just drops any data in the TCP buffer. Even you have a perfect network when the producer crashes or restarts, all messages in the socket buffer are gone.
Kafka producer API is async, it has a memory buffer. Kafka also has a socket buffer which can be tuned by “socket.send.buffer.bytes” (SO_SNDBUF). In case of a network failure, messages in the socket buffer could be lost; in case of a producer crash, all messages in the two buffers are gone.
Due to the volatility of buffers, a message is deemed as sent only when the ACK is received. Both RabbitMQ and Kafka provide callbacks(ACK).
When using Kafka, you probably need to limit the buffer size (“buffer.memory”) or shorten the wait time (“linger.ms”). When you generate events too fast or you have too many busy producers in one JVM process, your producer could run out of memory and crash. Of course, if you want the best reliability, you need to flush the buffer and acknowledge for every single message, definitely, your application will be slowed.
Producer-Broker ACK in RabbitMQ
RabbitMQ uses the term “Publisher Confirm” for ACK, and “Publisher Return” for NACK. From the official doc, it says:
Once a channel is in confirm mode, both the broker and the client count messages (counting starts at 1 on the first confirm.select). The broker then confirms messages as it handles them by sending a basic.ack on the same channel. The delivery-tag field contains the sequence number of the confirmed message
When programing in Java, it looks like this
channel.confirmSelect(); // enable confirm
channel.basicPublish(exchange, queue, properties, body);
// option 1, blocking, wait for ACK(Confirm) and NACK(Return)
channel.waitForConfirmsOrDie(5000);
// option 2, non-blocking
channel.addConfirmListener((sequenceNumber, multiple) -> {
// code when message is confirmed (ACK)
}, (sequenceNumber, multiple) -> {
// code when message is returned (NACK)
});
At the broker side, for a persistent queue, the ACK (confirm) message is returned only after the message is persisted to disk. If you have mirror queues, that means all mirrored queues have this message persisted. If you have quorum queues, that means over half of the queue replicas have this message persisted. For a transient queue, the ACK message is returned once it’s enqueued into broker’s memory.
A NACK (return) message is returned when a “mandatory” message is un-routable, or the destination queue is full. And I strongly suggest setting “mandatory=true” for reliable messages. Without this option, if a message is not routable, it will be discarded silently. Enabling it will cause a “basic.return” (negative confirm) to acknowledge the producer.
AMQP protocol provides transaction to ensure message published reliably but I strongly suggest not using it because it will decrease the throughput 250x.
Producer-Broker ACK in Kafka
Kafka uses the term “callback” for ACK. Below is the API for a callback.
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
In Kafka Java client, send() accepts a callback and returns a Future, when send() returns it does not mean it is “sent”, it means it’s in buffer now. Then Sender.run() loops to check the responses by NetworkClient.poll(). If any response is completed (the message has left an in-memory buffer or socket buffer, ACK polled), it executes your callback in the Sender thread. At this moment, your message is “sent”.
You can also use flush() in Kafka client, it will drain the memory buffer and socket buffer for all topics, and wait for all batches to complete with ACK from brokers, and all callbacks are executed, then it returns. flush() and callback share the same code path but flush() is synchronous and affects all topics, callback is per message and asynchronous, so use callback whenever possible.
Messages and Database Transaction
When we need to send a message and commit some database changes, there is a dilemma, shall we send the message in the transaction, or after the transaction?
The diagram below shows the 1st option, sending the message within the transaction. The message is sent before the transaction is committed. The problem is, if the transaction is rolled back at step 5, the message has been sent and there is no way to recall the message. The consumer will receive a phantom message referencing some phantom data.
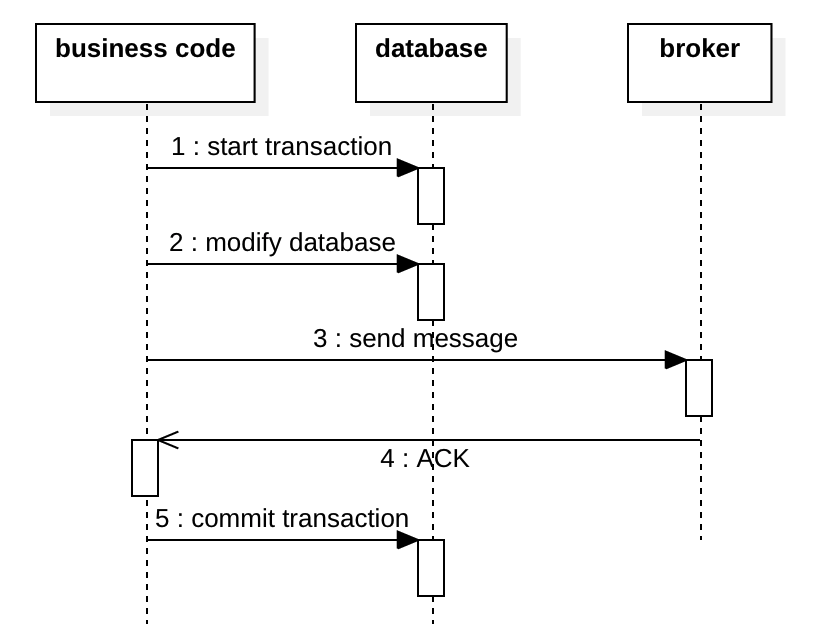
The diagram below shows the 2nd option: sending a message after the transaction. This is problematic too, if the sending at step 4 fails, the downstream system will never receive the message.
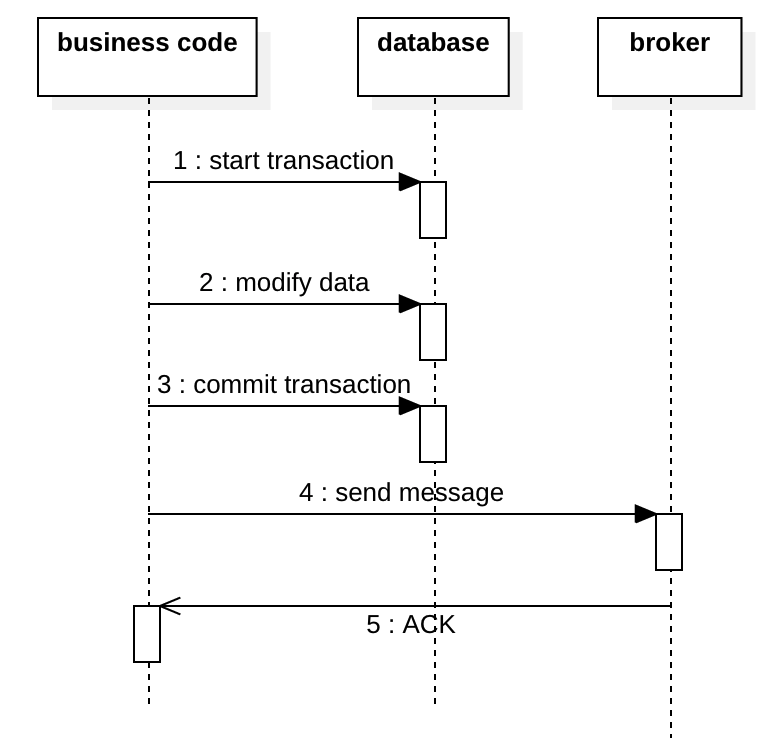
To solve this problem, Dan Pritchett, the architect of eBay first published a paper [1] about the outbox pattern, and it has been widely used eversince. In this pattern, we have an outbox table to hold messages to be sent. The message is committed along with the database transaction, this ensures the message is persisted with business data atomically. Then an async job scans the pending messages and publishes them to the broker, if succeeds, update the message as “sent” and archive it later.
Outbox Messaging Pattern
Below is the process of the outbox pattern.
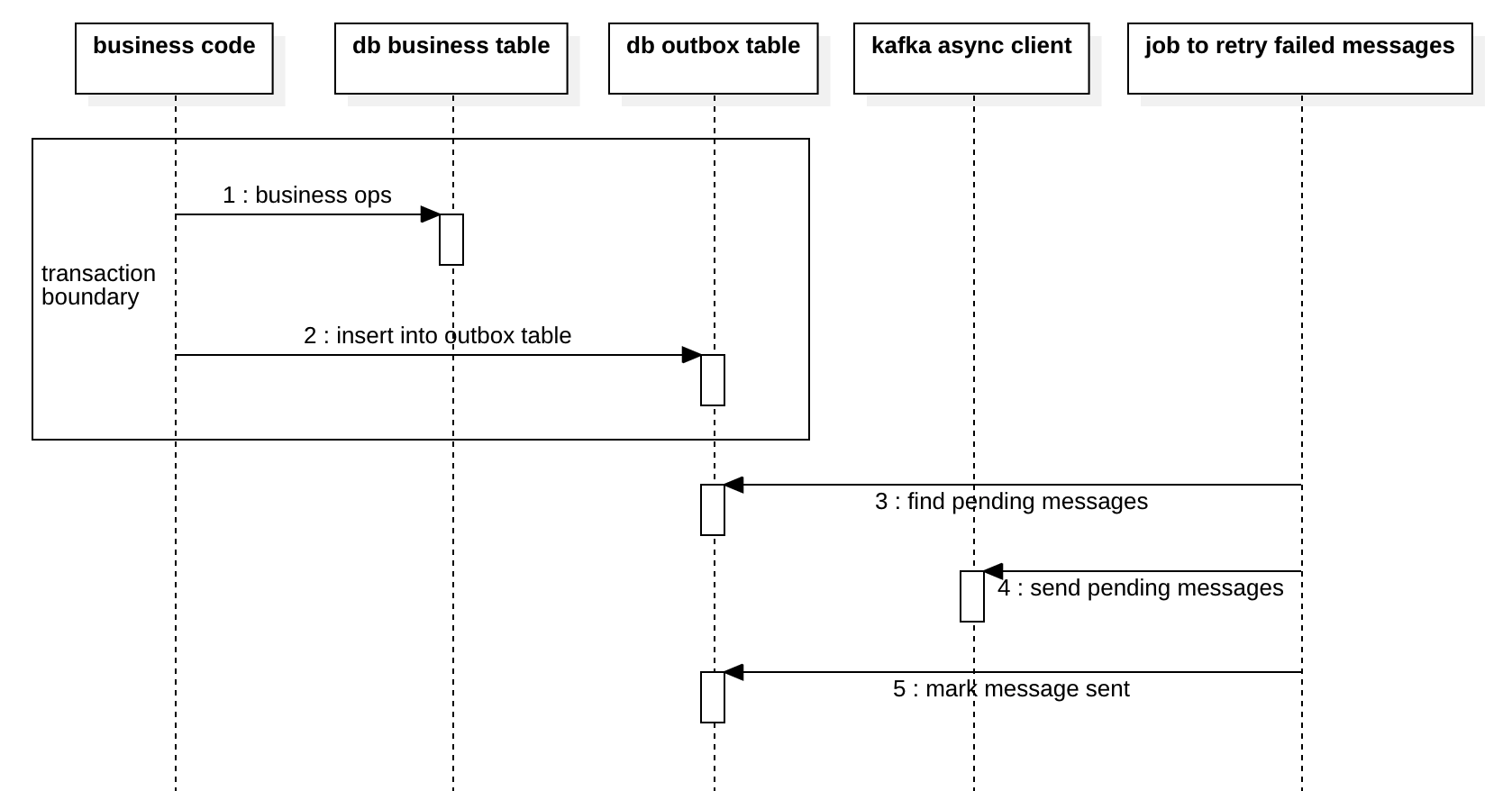
When implementing the outbox pattern, developers often misunderstand “sent” at step 4, and still lose messages in some scenarios. The major reason is producer and broker normally use local buffers, we will talk about this in the next two sections: Producer Buffer and Broker Buffer.
Because the job has a scheduled interval, the message will be sent in batch in intervals, which could cause high latency. So, we can also optimize a little bit to lower the latency as in the diagram below, we immediately trigger the job at step 3. But, this optimization is not applicable to strict total ordering, we will discuss it later in this article.
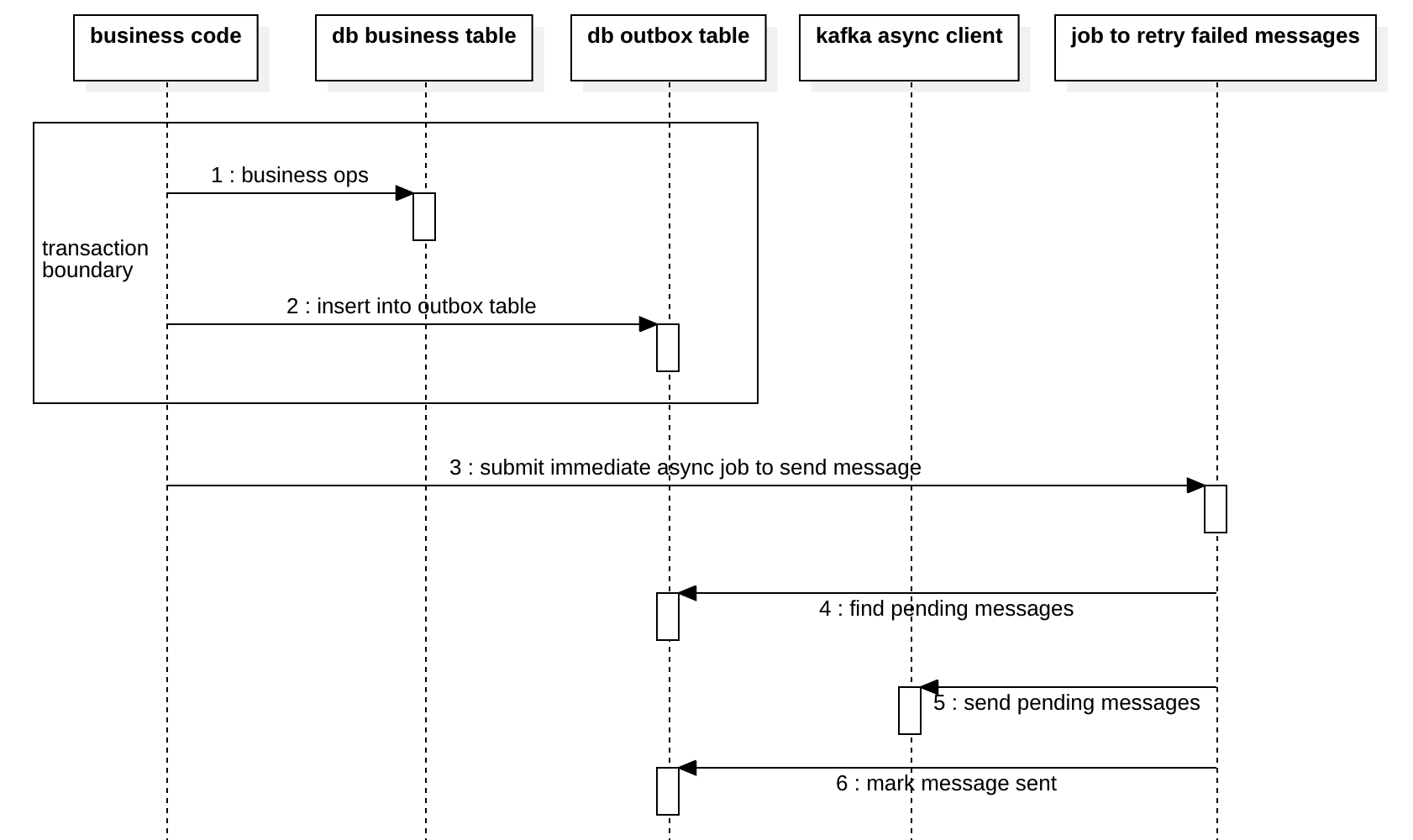
Note, when implementing the outbox pattern, one of the difficulties is to have the service instances coordinate to run the job to find pending or failed messages and publish them. This is often done with the help of zookeeper or etcd, to elect a leader for it. So this is somehow slow with a single leader doing all the jobs. Maybe you can have multiple outbox tables and hence a leader for each outbox to avoid contention. But this will break message ordering and we will talk about this later.
Another problem is when you have the low latency optimization at step 3 in the diagram above, you need to avoid step 3 and step 4 occurs at the same time for the same message. To avoid this, using some sort of external locking is too expensive, we can make the job just scan much older pending messages to avoid sending duplicated messages.
Many developers perfer using a column in each table to indicate if the message has been sent to avoid using an outbox table which requires extra space and disk IO operations. But this optimization is only available in limited scenarios. First, the message is closely coupled with your database design so it’s only for simple scenarios, it’s difficult to decide which table to add the column when your transaction involves many tables. Secondly, your data must be immutable (once written, never change, e.g, a ledger table), otherwise when you send the message, the message could have been changed several times and you will not be able to rebuild the original message.
Lastly, you need to pay attention to poison messages which always fail in the scanning job, you need to handle that correctly to avoid blocking other messages. e.g, Move the poison messages to another system or send email alerts to your Ops team.
Broker 2PC Pattern
Due to the three difficulties we mentioned above, RocketMQ provides a very different solution. It sends a “half-message” or “prepare-message” to the broker, only after the half-message is acknowledged you continue your database transaction. Once you finish your transaction and notify the broker at step 5 in the diagram below, the half-message is delivered to the consumer.
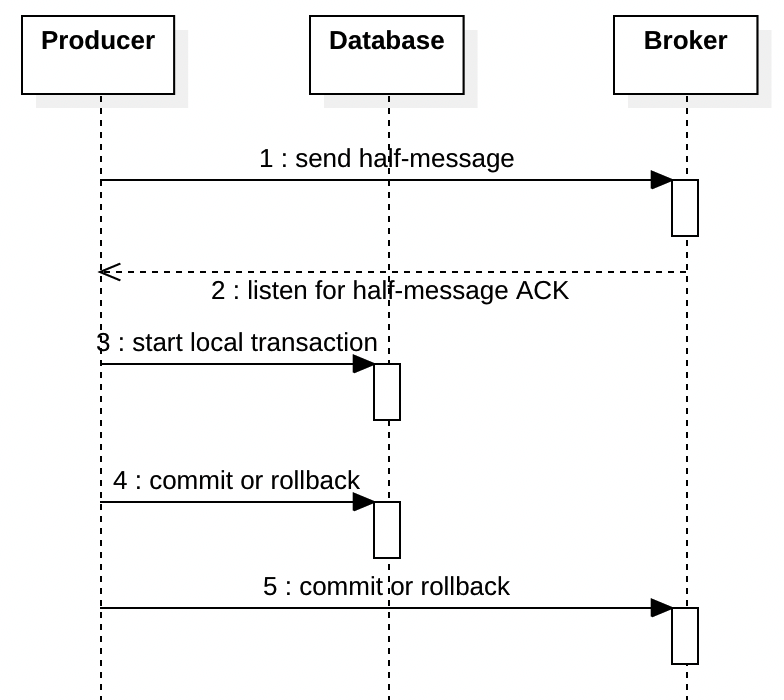
If the transaction is rolled back at step 4, the producer should notify the broker at step 5 then the broker will cancel the message and the consumer will never see it.
If the producer crashes at step 5, the broker will try to query the producer to check if the transaction should be committed or rolled back. Then the broker ensures the database and the broker are consistent.
Compared to the outbox pattern, this pattern simplifies your code, and it’s also faster since sending messages to the broker is often faster than inserting a record into the outbox table. But it has a major drawback. When the broker is down, since the “prepare message” cannot be acknowledged the transaction will fail even the database is still healthy. While with the outbox pattern, the transaction can be committed and processed later when the broker is recovered.
Personally I would prefer outbox pattern. The three difficulties of implementing the outbox pattern can be done by frameworks and in most cases I the database transaction get committed even if the broker is temporarily down.
Broker Durability
Broker Buffer
Even we have ACK between broker and producer, it’s still possible to lose the message on the broker side. It depends on how the broker replies ACK. If the broker replies ACK when the message is not persisted to disk yet, so a node crash at this moment will cause the messages in the broker buffer lost.
RabbitMQ only returns ACK after the message is “persisted”, so when the producer receives the ACK it’s affirmed that the message has been persisted. If you are using mirror queues, that means the messages have been persisted in all mirrors. If you are using quorum queues that means over half of the replicas have persisted the message.
Kafka returns ACK after the message is in the buffer, at that moment the message is not necessarily persisted to the disk yet. So you must set up replications to avoid message loss.
So, again, it’s a trade-off between performance and reliability.
Durability with Cache
At the broker side, each node has three tiers of the cache. OS cache, RAID cache, and disk internal cache.
The OS page cache can be controlled by fsync(), broker calls fsync() periodically, or when ACK’ed (RabbitMQ confirm). Some brokers like Apache Qpid has O_DIRECT option on fopen() to disable the page cache. But this is only in case you have RAID cache, otherwise, your system will be extremely slow although you have data safety.
The RAID cache is wired on the RAID card, it cannot be controlled by the operating system. If you don’t have BBU you probably need to set the RAID cache policy to write-through which is quite slow. To improve write performance you’d better have BBU and set the cache policy to write-back (write-behind).
The disk internal cache is a very small cache inside the disk, about 32MB to 128MB, if you are using a RAID card with BBU and you can disable it. Note, some new disks have a non-volatile disk cache, in that case, you can enable it and you will have two layers of non-volatile cache.
With a safe cache policy configured, it’s still possible that your server crashes with some hardware failure. So most brokers have replication support. RabbitMQ has mirrored queues to replicate messages, Kafka has partitions and each partition has multiple replications across the cluster. So, next, let’s talk about the durability of replications.
Durability with Replication
RabbitMQ has a concept of mirrored queues for replication. Each mirrored queue consists of one master and one or more mirrors. All operations for a given queue are first applied on the queue’s master node and then propagated to mirrors. This involves enqueueing publishes, delivering messages to consumers etc. ACK (confirm) is sent back to the producer from the leader node after all nodes have the message persisted, that’s a very strong guarantee although very slow.
By default, if a queue’s master node fails, the oldest mirror will be promoted to be the new master. In some circumstances, this mirror can be unsynchronised, which will cause data loss. If you always use confirm (producer ack) and mirrored queues, since we receive confirm (ack) only after messages are persisted on all nodes, we don’t need to worry about the data synchronization across nodes. For mirrored queues without publisher confirm, you probably encounter the unsynchronized queues. In that case, if you want consistency, you need to set ha-promote-on-failure to when-synced, and try to recover the failed node manually. If you want availability, you can set it to always, then try to re-send the messages that could be lost.
RabbitMQ also provides Quorum Queues which is easier to maintain data safety.
Kafka’s partitions replication is similar to mirror queues, but the ACK modes are much more flexible, the message is ACK’ed and persisted in 3 modes:
acks=0: the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent.
acks=1: The leader will write the record to its local log but will respond without awaiting full acknowledgment from all followers. In this case, should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.
acks=all: This means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee.
So, for reliable messaging you probably need acks=all in case a server crashes and cannot get back timely.
Setting acks=all is really slow, if you want better performance, you can set acks=1, then disable “unclean election”. Then in case of a leader crash, if there is no in-sync replica the partition will be unavailable until the leader recovers. (see unclean.leader.election.enable). It’s a trade-off between availability and consistency. Actually, I would like to choose availabilities with best-effort consistency. That is, set acks=1 and enable “unclean election”. if we have property monitoring (e.g. UncleanLeaderElectionsPerSec in Prometheus) we can detect unclean election, then we can revert the status of the recent messages in the outbox to “PENDING” and send them again to avoid messages lost. But this will break the ordering guarantee in each partition. We will talk about order later in this article.
Consumer Reliability
On the consumer side, often we need the message processed with the database transaction atomically. In another word, if the message ACK fails, don’t commit the transaction, if the message is ACK’ed, we must commit the transaction.
If we ACK the message before the transaction, we could consume the message without triggering the business code to modify the database, obviously this is unacceptable.
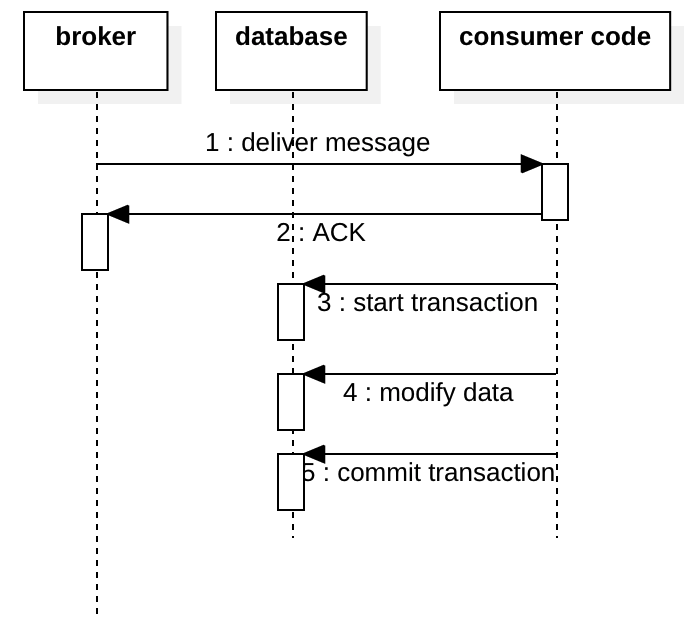
If we ACK the message in the transaction, we suffer the same problem as we ACK the message before the transaction. If we fail to commit the transaction at step 5 in the diagram below, since the message is ACK’ed, we will never have another chance to consume it again, the data in the database will never be updated.
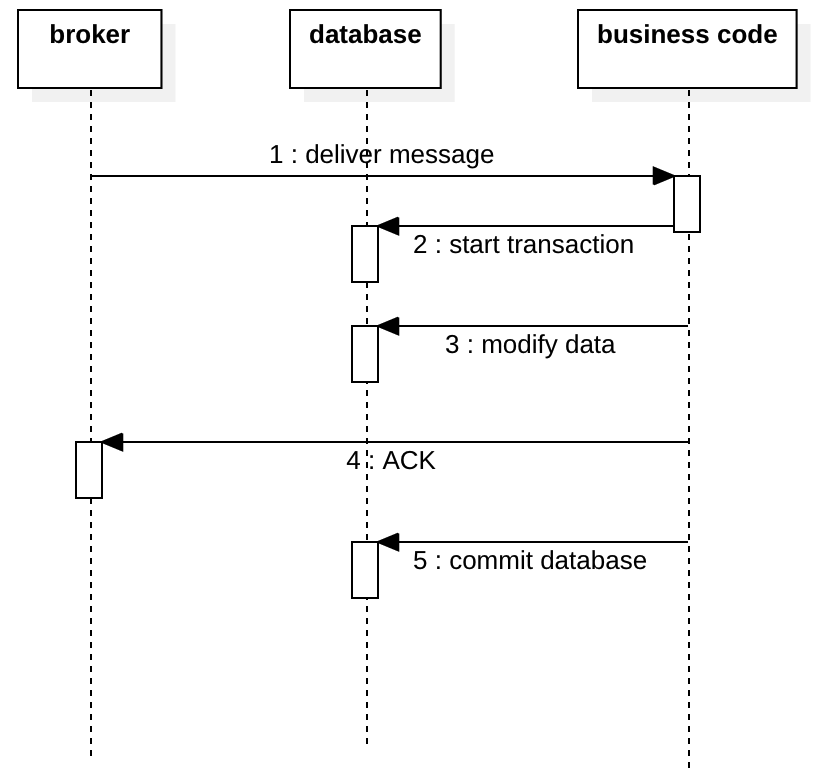
The better way to handle this is to ACK the message after the transaction. If the transaction is committed but the message is not ACK’ed, we will consume it later again. If only your message processing is idempotent, or you have the capability to deduplicate the message, you achieve exactly-once. See the diagram below:
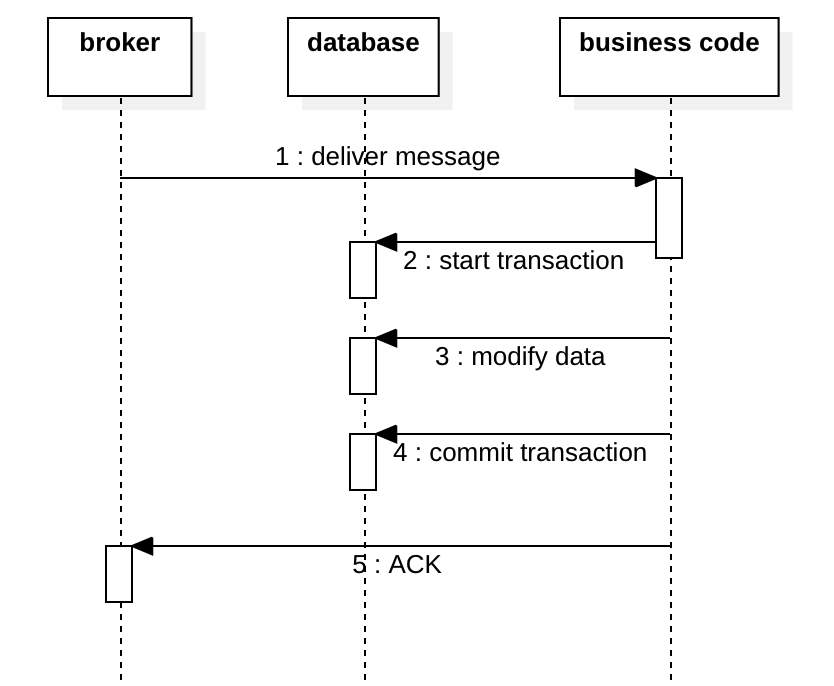
However, the consumer ACK is also a little complicated, many people do not understand it correctly.
Consumer ACK mode
In AMQP, there is an auto ack mode, you must disable it and manually ACK the message. Spring has a “auto ack” feature, but it is totally different from the concept of “auto ack” in AMQP. For more details please refer to Spring doc AcknowledgeMode.
In Kafka, you can commit synchronously or asynchronously.
void commitSync();
void commitAsync();
void commitAsync(OffsetCommitCallback callback);
It’s always recommended to use async because consumer ACK is not very crucial. If consumer ACK is lost, you just consume that message one more time. If only you can deduplicate it or your processing is idempotent, it’s just fine.
A special case is when you have to consume some messages, process them and then publish some of the results back to Kafka, you can use Kafka transaction. For more details, refer to Kafka Transaction.
Consumer Buffer
For RabbitMQ, the pre-fetch size is equivalent to the buffer size. AMQP has built-in flow control, if in-flight messages reach the pre-fetch size, the consumer stops consuming messages. You don’t need to write any code for this, AMQP rocks, right?
For Kafka, because it’s designed as a batch-pull pattern, there is no built-in flow control, we need to limit the consumer buffer size and stop pulling if the buffer is full, otherwise, the application will encounter OOM and crash, then your consumer(application) will be kicked out of the consumer group and re-join later. Sometimes the re-join and re-balance process could take 5 minutes, which is a severe problem. Even worse, if there is no message for a long period of time, it also could cause consumers kicked out from the consumer group. Too bad without flow control!
To build a reliable system with Kafka which does not provide built-in flow control, you need to write some sort of flow control on your own. e,g. when the buffer is almost full, you need to dynamically increase the pull interval, increase “max.poll.interval.ms”, or decrease “max.poll.records” from the consumer side. If you feel it’s too difficult to implement, just use a very smaller consumer buffer.
Poison Message
Sometimes there could be an invalid message in the queue, if the consumer cannot parse the message normally it simply throws an exception and re-queue the message. Then, the message will be delivered, parsed, and re-queued again and again. To build a reliable messaging system you must ensure that you have some method to detect this kind of poison message and drop it or publish it to other queues to avoid processing it infinitely.
Message Ordering
Many people talk about message ordering but often different people have different understandings of ordering. Here we define two different concepts of message orderings: the broker delivery order and the business event order.
Broker Delivery Order
Broker delivery order means, if a message A is delivered to the broker before B, then A should be consumed before B. In Kafka, messages in a single partition are delivered in order. With RabbitMQ, if you disable pre-fetch at the consumer side, having a single consumer, and only process one message each time, then most likely you have a broker delivery order. It’s very inefficient to guarantee the broker delivery order. Believe it or not, in most cases, the broker delivery order is useless. We will explain why later.
Business Event Order
Business event order means the messages are produced and processed in the causal order. e.g, your deposit account changes from $0 to $1000, then $1000 to $500, the downstream message consumers must be able to identify the event in the transaction order. If the downstream receives the event $1000 to $500 first, then $0 to $1000, it must be able to identify the two messages are out of order, and reorder them before processing them.
On the other hand, if two transactions applied on two accounts, and the transactions are not between the two account, then we can say the there is no causal relationships between the two transactions, the consumer can process the two events in whatever order. e.g, the event A means withdraw on account X , the event B means deposit on account Y, the two events are irrelevant, no causal relationships, the consumer can process them in whatever order. If the two transactions are transferring money between X and Y, then they are causally related, we need to re-order and process the two messages in the business event order.
Sometimes, we don’t really need a full message history and you can drop some of them. e.g, we use the messaging system to track the number of visitors in a super market. If we receive a message saying 200 visitors, then a message saying 100 visitors, we can simply drop the second message, because the number of visitors are monotonically increasing. We don’t need a complicated state machine a full history of the business events.
So, business event order is to find the causally related messages, re-order, drop and process them in the expected business order. The business event order is the order you really need.
What Kind of Ordering You Need?
Suppose we have two producers P1 and P2, and a consumer C. P1 sends m1, then P2 sends m2, and there is causal relationship between m1 and m2, in another word, m1 must be processed before m2.
Look at the diagram below, the consumer will consumer m1 first, then m2, perfect, right?
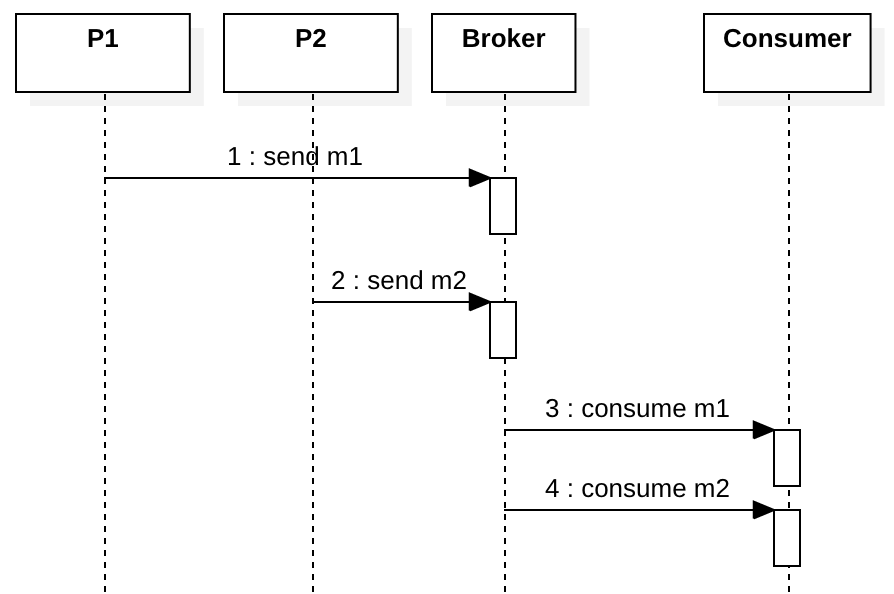
Now let’s consider the case when m1 fails. If m1 is re-sent later at step 3, although we have perfect broker delivery order, the consumer consumes messages in the wrong business event order.
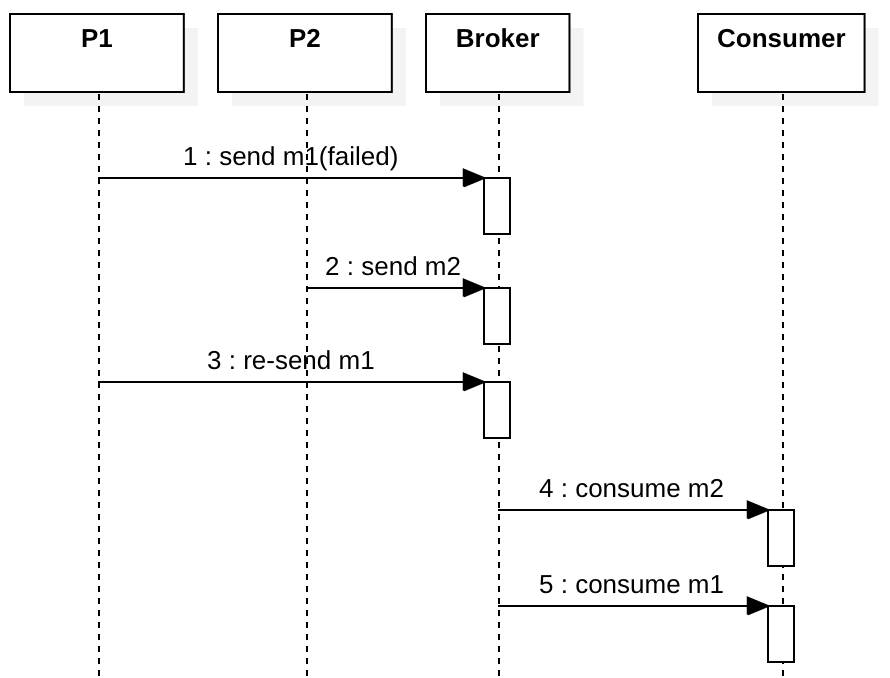
This is a very simple example telling you that broker delivery order is totally useless, and it harm the throughput of your system[1]. What you really need is the business event order, probably in causal relationship, which often arrives at the broker out of order.
If you have multiple consumers they also need to handle messages in the business event order carefully. e.g, the diagram below shows that a consumer C1 receives m1, then C2 receives m2. Ideally, C2 should receive m2 after m1 is processed by C1. Without locking, m1 and m2 could be processed in parallel which violates the business event order.
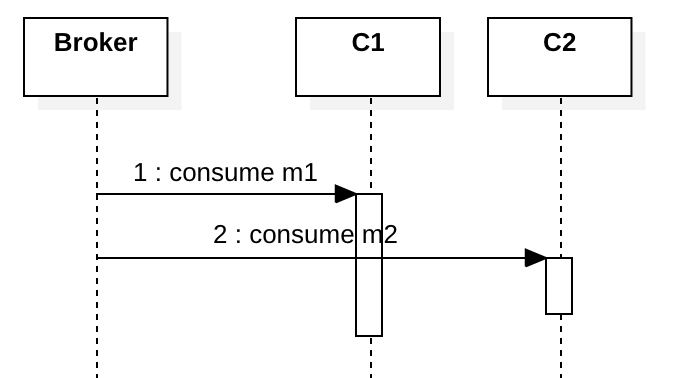
To process messages in the business event order, you don’t really need a global lock or start a single consumer, these solutions provide linearizability consistency but they are too slow and unnecessary in most cases. Actually we only care about the causally related messages which must be processed in the business event order. To do so, we can have state machines for those causally-related messages at the consumer side, if a message arrives out of order (too early), we can store it locally in an “inbox”. Later, when the delayed message arrives, we trigger the state machine to the next state, then check the inbox to see if the next expected message has been there.
Recap, you don’t need broker delivery order which is meaningless, what you really need is the business event order, and you can use inbox and state machine at the consumer side to provide causal consistency message ordering. Never ever have your code depepends on the broker delivery order, it’s meaningless.
Conclusion
- Message reliability is not that easy as many people expected, you need to understand a lot of details including the buffers, cache, replication, leader election and failover.
- Exactly-once has to be implemented with idempotency or deduplication on top of at-least-once.
- Broker delivery order is meaningless, your application should be able to handle messages in the business event order, even the broker delivers them out of order.
References
- Dan Pritchett, Ebay “Base: An Acid Alternative” ACM QUEUE May/June 2008