![]()
fast-object-pool
FOP,一个针对并发访问优化的轻量级高性能对象池,您可以使用它来池化昂贵且非线程安全的对象,例如 thrift 客户端等。
Github repo: https://github.com/DanielYWoo/fast-object-pool
Site page: https://danielw.cn/fast-object-pool/
为什么还要搞一个对象池
FOP 使用分区实现以避免线程争用,性能测试表明它比 Apache commons-pool 快得多。 本项目不是为了替代 Apache commons-pool,本项目没有提供 commons-pool 丰富的功能,本项目主要针对: 1.零依赖(唯一可选的依赖是disrutpor)
- 并发请求/线程多的高吞吐量
- 更少的代码,所以每个人都可以阅读和理解它。
配置
首先,您需要创建一个 FOP 配置:
PoolConfig config = new PoolConfig();
config.setPartitionSize(5);
config.setMaxSize(10);
config.setMinSize(5);
config.setMaxIdleMilliseconds(60 * 1000 * 5);
上面的代码意味着池中至少有 5x5=25 个对象,最多 5x10=50 个对象,如果一个对象超过 5 分钟没有被使用,它可以被删除。
然后定义如何使用 ObjectFactory 创建和销毁对象
ObjectFactory<StringBuilder> factory = new ObjectFactory<>() {
@Override public StringBuilder create() {
return new StringBuilder(); // create your object here
}
@Override public void destroy(StringBuilder o) {
// clean up and release resources
}
@Override public boolean validate(StringBuilder o) {
return true; // validate your object here
}
};
现在您可以创建 FOP 池并使用它
ObjectPool pool = new ObjectPool(config, factory);
try (Poolable<Connection> obj = pool.borrowObject()) {
obj.getObject().sendPackets(somePackets);
}
关闭对象池
pool.shutdown();
安装使用
Maven:
<dependency>
<groupId>cn.danielw</groupId>
<artifactId>fast-object-pool</artifactId>
<version>2.2.1</version>
</dependency>
Gradle:
implementation 'cn.danielw:fast-object-pool:2.2.1'
如果您想要获得最佳性能,您可以选择将Disruptor添加到您的依赖项中,并使用 DisruptorObjectPool 而不是 ObjectPool。
For JDK 11+, 使用以下Disruptor依赖.
Maven:
<dependency>
<groupId>com.conversantmedia</groupId>
<artifactId>disruptor</artifactId>
<version>1.2.19</version>
</dependency>
Gradle:
implementation 'com.conversantmedia:disruptor:1.2.19'
Logging
FOP 的设计目标之一是零依赖,所以默认使用 JDK logger。如果您使用 slf4j,您可以选择将 jul-to-slf4j 添加到您的依赖项中,以将 JDK 记录器桥接到 slf4j。
工作原理
FOP会创建多个分区Pool,大多数情况下一个线程总是访问一个指定的分区,因此,您拥有的分区越多,遇到线程争用的可能性就越小。 每个分区都有一个阻塞队列以保存可池对象;借用一个对象,队列中的第一个对象将被移除;返回一个对象会将该对象附加到队列的末尾。 这个想法来自ConcurrentHashMap的segments设计和 BoneCP 连接池的分区设计。该项目从 2013 年开始,已经部署到许多项目中,没有任何问题。
How fast it is
源代码中包含一个基准测试,您可以在自己的机器上运行它。 在我的 Macbook Pro(8 核 i9)上,它比 commons-pool 2.2 快 50 倍。
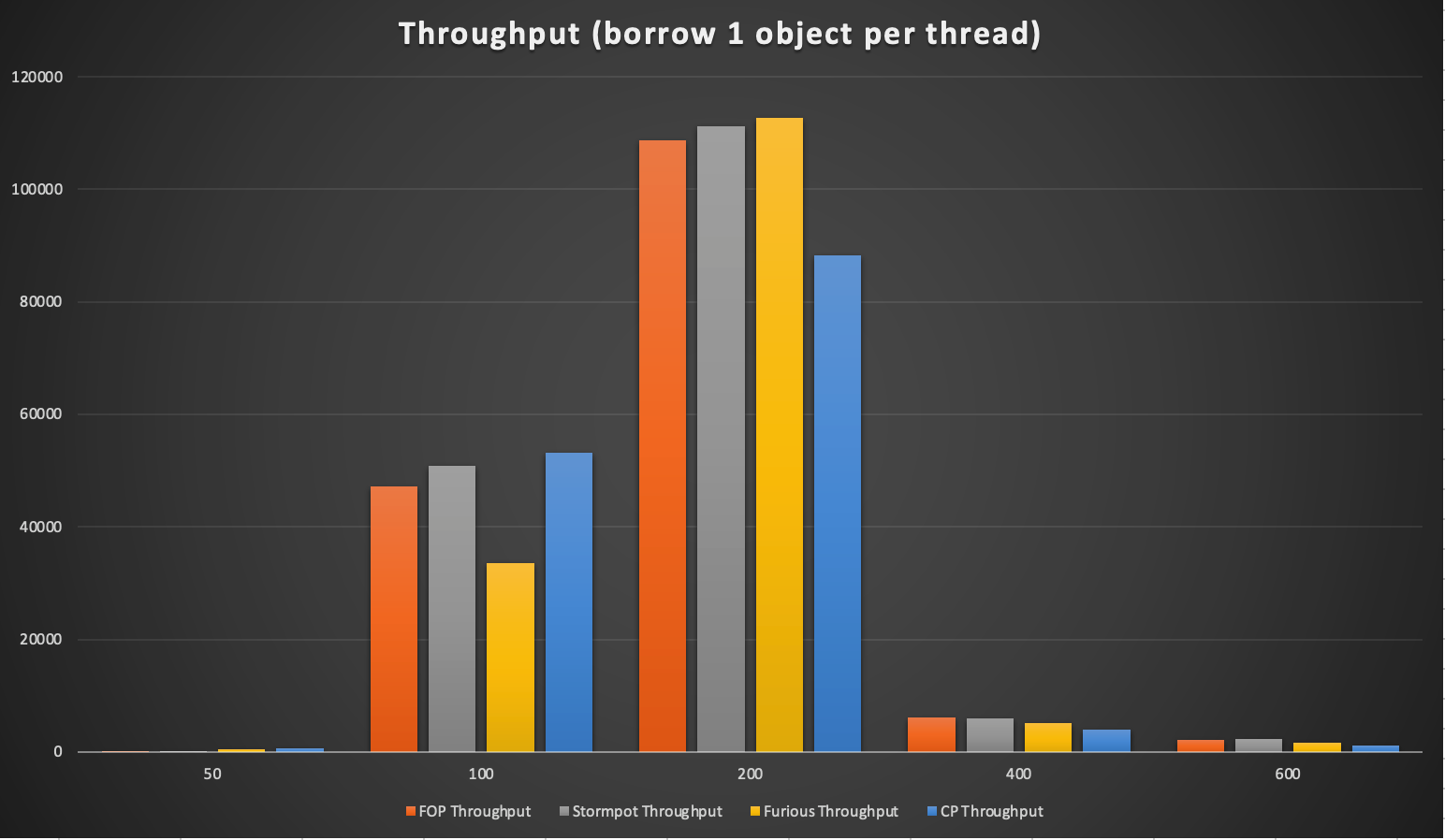
测试用例1:我们有一个256个对象的池,使用50/100/400/600个线程在每个线程中每次借用一个对象,然后返回池中。
下图中的 x 轴是线程数,可以看到 Stormpot 提供了最好的吞吐量。 FOP 紧随 Stormpot 之后。 Apache common pool 很慢,Furious 比它快一点。
您会看到 200 个线程后吞吐量下降,因为只有 256 个对象,因此会有更多线程的数据竞争和超时。
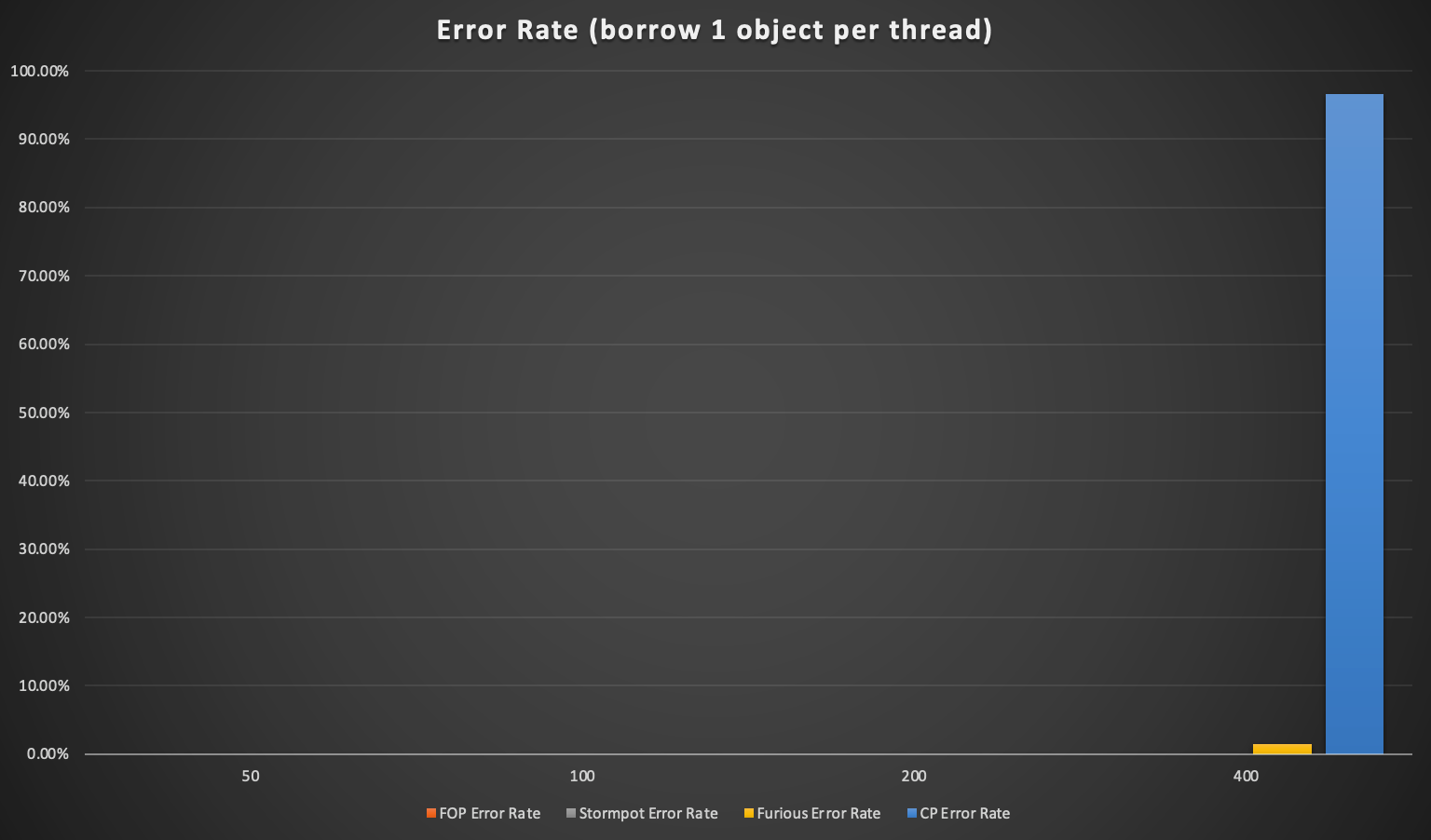
 当你有 600 个线程竞争 256 个对象时,Apache common pool 的错误率达到了 85% 以上(可能是返回太慢了),基本上不能用于高并发。
当你有 600 个线程竞争 256 个对象时,Apache common pool 的错误率达到了 85% 以上(可能是返回太慢了),基本上不能用于高并发。
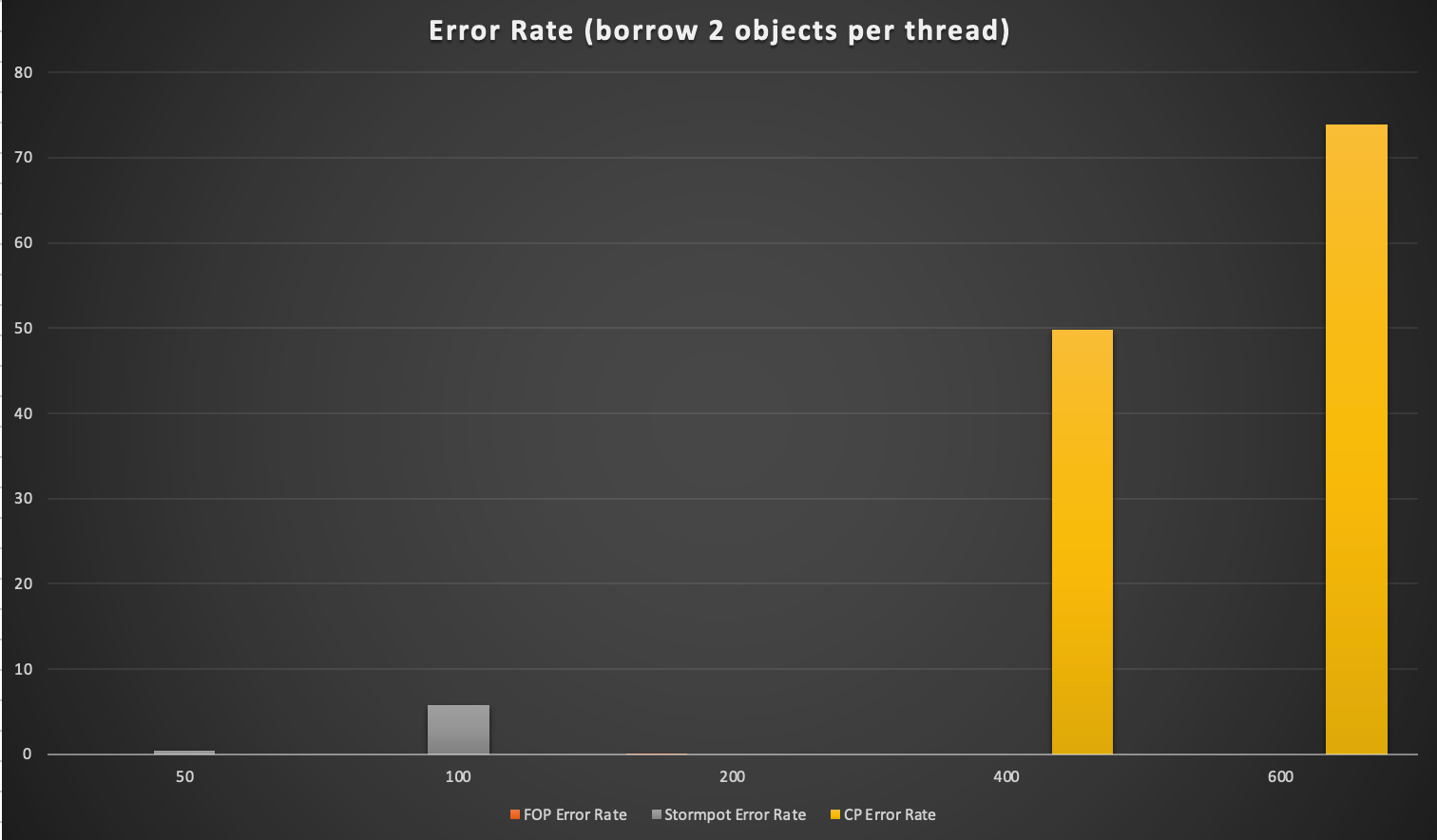
上图如果每个线程一次只借一个对象,如果你需要在一个线程中借两个对象,事情就变得更有趣了。
测试用例 2:我们有一个 256 个对象的池,使用 50/100/400/600 个线程,每次每个线程借用两个对象,然后返回池中。
在这种情况下,我们可以同时需要 600x2=1200 个对象,但只有 256 个可用,因此会出现数据竞争和超时错误。
FOP 保持稳定的错误率,但 Stormpot 在 100 个线程时开始看到 7% 的错误率。 (我不能用 600 个线程测试stormpot,因为它太慢了)
Furious 似乎无法工作,因为我找不到设置超时的方法,没有超时控制导致 Furious 循环死锁,
所以我从下图中排除了 Furious。 FOP 和 Stormpot 都提供了超时配置,在测试中我将超时设置为 10ms。
FOP 抛出异常,Stormpot 返回 null,因此我们可以将其标记为失败(显示在错误率图中)。
同样,Apache common pool 几乎达到了 80% 的错误率,基本上无法正常工作。
FOP 的吞吐量也比其他池好很多。有趣的是,在这种情况下,Apache common pool 比 Stormpot 稍快。
我不知道为什么 Stormpot 在一个线程中有两次借用时降级如此之快。如果您知道如何针对这种情况优化 Stormpot 配置,请告诉我。
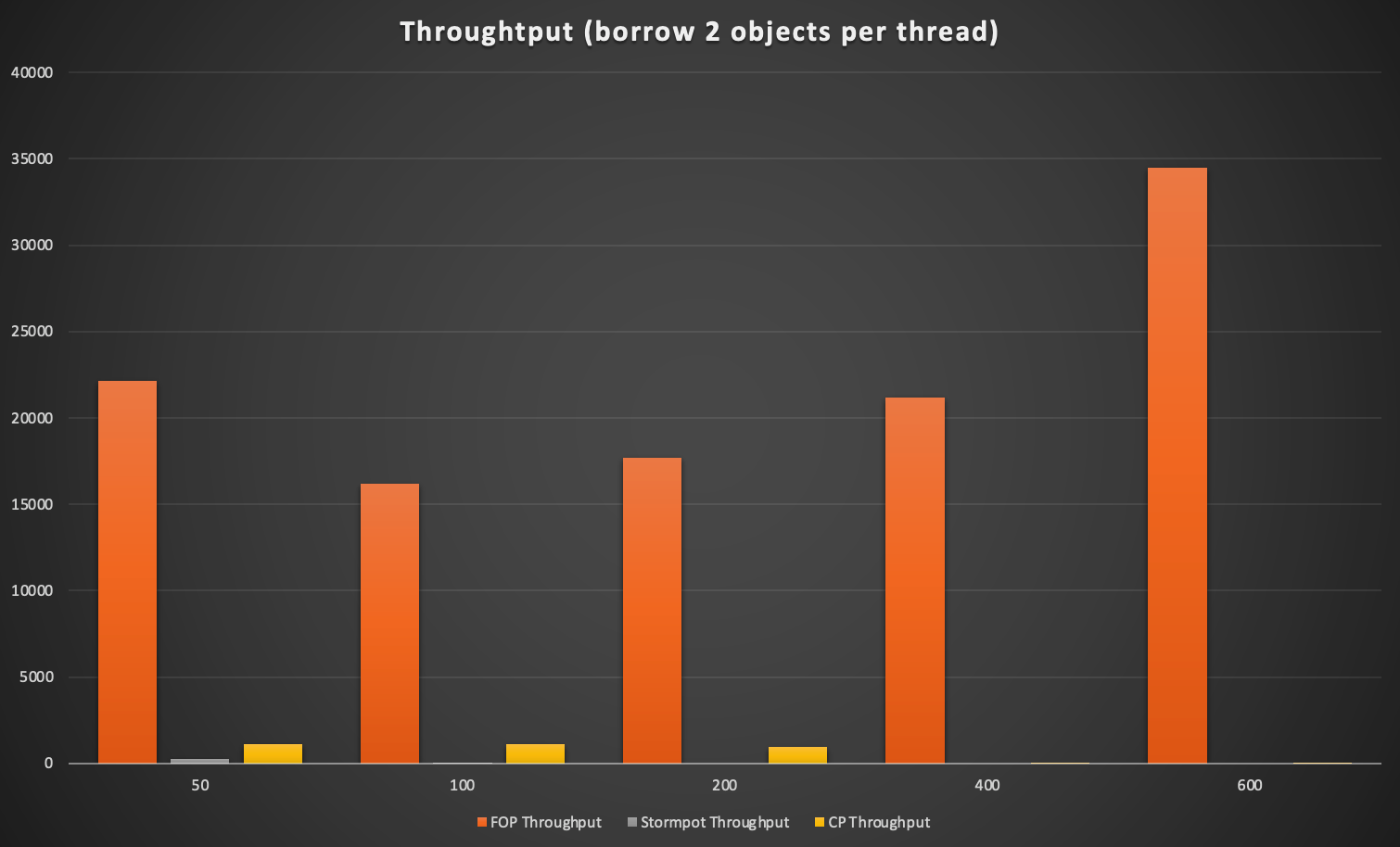
所以,简而言之,如果你能保证在每个线程中最多借一个对象,Stormpot 是最好的选择。如果您无法确保这一点,请使用在所有情况下都更加一致的 FOP。