分布式系统中的网络模型和故障模型
因为分布式系统的网络模型和故障模型在我的博客中可能会经常被引用, 所以我写了本文作为一个引用文章.
分布式系统中的网络模型
- 同步网络(synchronous network): 这里的同步网络和编程中的同步阻塞io和异步非阻塞io是两回事, 不要弄混了. 同步网络是指i). 所有节点的时钟漂移有上限, ii). 网络的传输时间有上限, iii). 所有节点的计算速度一样. 这意味着整个网络按照round运行, 每个round中任何节点都要执行完本地计算并且可以完成一个任意大小消息的传输. 一个发出的消息如果在一个round内没有到达, 那么一定是网络中断造成的, 这个消息会丢失, 不会延迟到第二个round到达. 在现实生活中这种网络比较少, 尽管很少, 同步网络仍然是在计算机科学中是不可缺少的一个分析模型, 在这种模型下可以解决一些问题, 比如拜占庭式故障. 但我们每天打交道的网络大多都是异步网络.
- 异步网络(asynchornous network): 和同步网络相反, 节点的时钟漂移无上限, 消息的传输延迟无上限, 节点计算的速度不可预料. 这就是我们打交道的网络类型. 在异步网络中, 有些故障非常难解决, 比如当你发给一个节点一个消息之后几秒钟都没有收到他的应答, 有可能这个节点计算非常慢, 但是也可能是节点crash或者网络延迟造成的, 你很难判断到底是发生了什么样的故障.
fault, error and failure
这不是绕口令, 你一定要区分他们的关系. 过去很多时候这些词汇混用导致很多问题, 后来统一了这几个词的定义: Fault: 在系统中某一个步骤偏离正确的执行叫做一个fault, 比如内存写入错误, 但是如果内存是ECC的那么这个fault可以立刻被修复, 就不会导致error. Error: 如果一个fault没能在结果影响到整个系统状态之前被修复, 结果导致系统的状态错误, 那么这就是一个error, 比如不带ECC的内存导致一个计算结果错误. Failure: 如果一个系统的error没能在错误状态传递给其它节点之前被修复, 换句话说error被扩散出去, 这就是一个failure.
所以他们的关系是fault导致error, error导致failure. 在分布式系统中, 每个节点很难确定其它节点内部的状态, 通常只能通过和其他节点的交互监测到failure. 接下来我们所说的故障一般都是指failure.
分布式系统中的故障模型
在分布式系统中, 故障可能发生在节点或者通信链路上, 下面我们按照从最广泛最难的到最特定最简单的顺序列出故障类型:
- byzantine failures: 这是最难处理的情况, 一个节点压根就不按照程序逻辑执行, 对它的调用会返回给你随意或者混乱的结果. 要解决拜占庭式故障需要有同步网络, 并且故障节点必须小于1/3或者消息传递过程中不可篡改,通常只有某些特定领域才会考虑这种情况通过高冗余来消除故障. 关于拜占庭式故障你现在只要知道这是最难的情况, 稍后我们会更详细的介绍它.
- crash-recovery failures: 它比byzantine类故障加了一个限制, 那就是节点总是按照程序逻辑执行, 结果是正确的. 但是不保证消息返回的时间. 原因可能是crash后重启了, 网络中断了, 异步网络中的高延迟. 对于crash的情况还要分健忘(amnesia)和非健忘的两种情况. 对于健忘的情况, 是指这个crash的节点重启后没有完整的保存crash之前的状态信息, 非健忘是指这个节点crash之前能把状态完整的保存在持久存储上, 启动之后可以再次按照以前的状态继续执行和通信.
- omission failures: 比crash-recovery多了一个限制, 就是一定要非健忘. 有些算法要求必须是非健忘的. 比如最基本版本的Paxos要求节点必须把ballot number记录到持久存储中, 一旦crash, 修复之后必须继续记住之前的ballot number.
- crash-stop failures: 也叫做crash failure或者fail-stop failures, 它比omission failure多了一个故障发生后要停止响应的要求. 比如一个节点出现故障后立即停止接受和发送所有消息, 或者网络发生了故障无法进行任何通信, 并且这些故障不会恢复. 简单讲, 一旦发生故障, 这个节点 就不会再和其它节点有任何交互. 就像他的名字描述的那样, crash and stop.
分布式系统中的故障类型还有其他的分类方法, 有些分类会把omission去掉, 有些会加入performance failures, 有些会把crash-stop和fail-stop根据故障检测能力区分开, 此处介绍的是使用较为广泛的一种分类方法. 他们的关系如下:
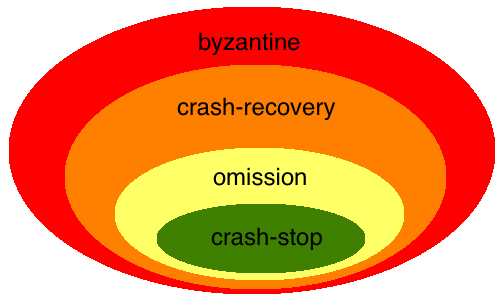
这四种故障中, 拜占庭式故障是非常难以解决的, Leslie Lamport证明在同步网络下,有办法验证消息真伪或者故障节点不超过1/3的情况下才有可能解决, 在现实中, 这类问题解决成本非常高, 只有在非常关键的领域才会考虑使用BFT(Byzantine Fault Tolerance)的设计. 比如NASA的航天飞机有5台可以抵抗各种射线影响的AP-101系列计算机, 其中四台使用同样的软件运行, 另外一台独立运行另外一个独立编写版本的软件. 空客A320有7台计算机, 分别是三种硬件上运行的三套独立编写的软件. 美国海军的海狼级核动力攻击型潜水艇(SSN-21)也采用了多组计算机控制. 绝大多数应用是不太考虑重力加速度和射线辐射对硬件的影响的. 大多数分布式应用主要是关注crash-recovery的情况, 而crash-stop是一种过于理想化的情况, 比如3PC的故障模型是基于crash-stop的, 但是在真实环境中crash-recovery会导致3PC的结果不一致.